
V-JEPA 2: O modelo de IA da Meta que aprende sobre o mundo assistindo vídeos
AIConheça o V-JEPA 2, o novo modelo de IA do Meta que aprende sobre o mundo físico assistindo a 1 milhão de horas de vídeos da internet.

Imagine tentar ensinar um robô a pegar uma xícara de café. A abordagem tradicional seria mostrar a ele milhares de exemplos de "como pegar uma xícara", talvez até controlando seus braços remotamente para que ele aprenda os movimentos exatos. Esse processo, chamado de aprendizado por imitação ou clonagem de comportamento, é poderoso, mas tem uma limitação fundamental: é incrivelmente caro e demorado. Você precisa de dados de interação de alta qualidade, e muitos deles.
E se, em vez disso, o robô pudesse primeiro aprender como o mundo funciona apenas... observando? E se ele pudesse assistir a um milhão de horas de vídeos aleatórios da internet — vídeos de pessoas cozinhando, cachorros brincando, carros passando — e, a partir dessa observação passiva, construir um modelo mental interno, uma espécie de "simulador de física intuitiva"?
Essa é a ideia central por trás do V-JEPA 2, um novo e fascinante modelo de IA apresentado pelo FAIR, o laboratório de pesquisa de IA da Meta. Publicado em um artigo de 13 de junho de 2025, o V-JEPA 2 não é apenas mais um modelo de vídeo; é um passo ambicioso em direção à criação do que os pesquisadores chamam de "Modelos de Mundo" (World Models). Trata-se de sistemas de IA que aprendem as regras subjacentes do mundo físico para entender, prever e, o mais importante, planejar ações de forma eficiente e generalizável, assim como os humanos fazem.
Neste post, vou mergulhar fundo na arquitetura do V-JEPA 2, entender como ele aprende, ver seus resultados em tarefas que vão desde o reconhecimento de ações até o controle de robôs, e fazer uma análise crítica de como ele se compara a outras abordagens de ponta da Google e da Nvidia.
O Dilema dos dados: Observação vs. Interação
O maior gargalo para criar robôs e agentes de IA verdadeiramente inteligentes sempre foi a coleta de dados. Modelos que aprendem exclusivamente a partir de dados de interação (pares de estado-ação, muitas vezes com um sinal de recompensa) são limitados pela escassez e pelo custo desses dados. É difícil escalar um método que requer milhões de trajetórias de robôs perfeitamente executadas no mundo real.
Por outro lado, o mundo está inundado de dados de observação: vídeos. O YouTube sozinho contém uma quantidade quase infinita de informações visuais sobre como os objetos se movem, interagem e se comportam sob várias condições. O desafio é que esses vídeos não vêm com rótulos de "ação". Quando você assiste a um vídeo de alguém abrindo uma porta, você não tem os dados precisos dos comandos neurais e motores que levaram àquela ação.
A genialidade da abordagem do V-JEPA 2 está em sua estratégia de duas etapas, que combina o melhor dos dois mundos, como podemos ver na visão geral da Figura 1 do artigo.
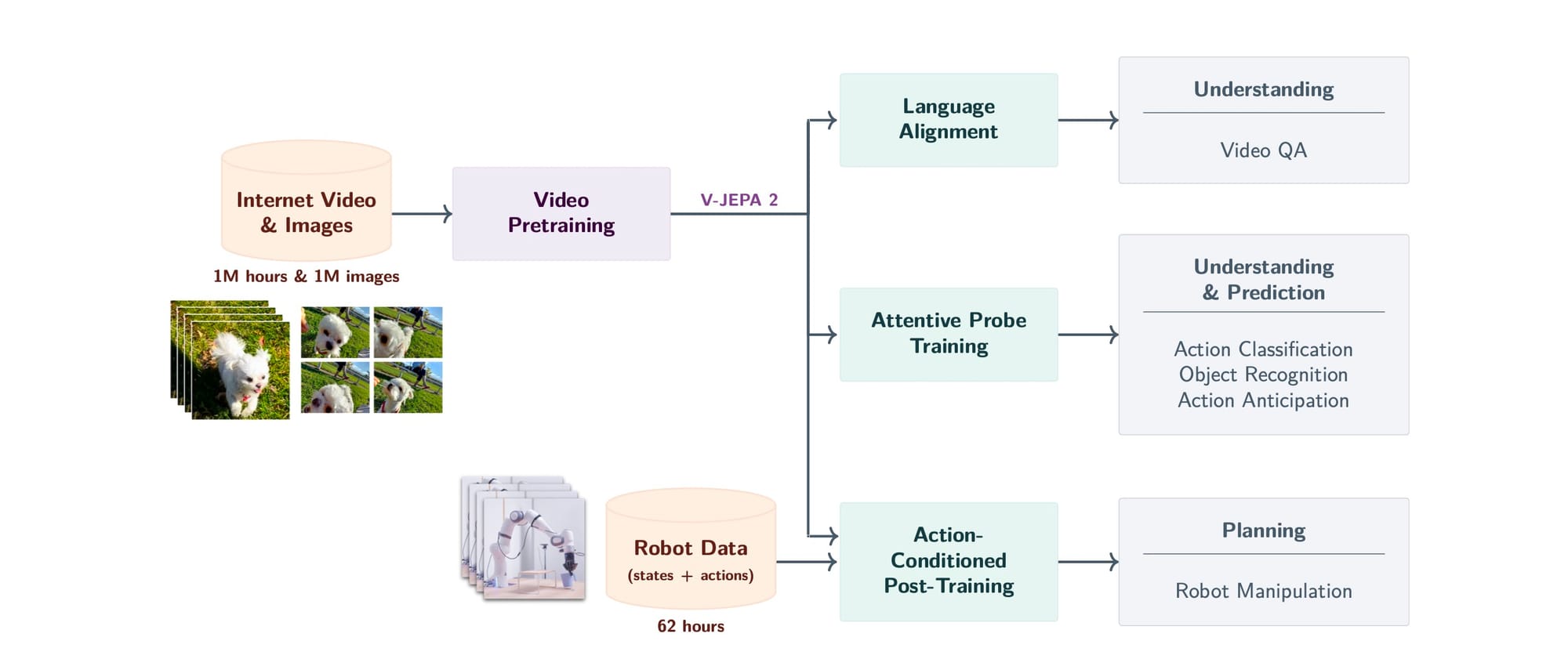
- Pré-treinamento massivo com observação: Primeiro, o modelo aprende um conhecimento de base sobre o mundo, assistindo a mais de 1 milhão de horas de vídeos e imagens da internet. Nesta fase, ele não aprende a agir, mas a entender e prever a dinâmica visual.
- Pós-treinamento eficiente com interação: Depois que o modelo já tem essa base sólida, ele é ajustado com uma quantidade muito pequena de dados de interação — menos de 62 horas de vídeos de um robô realizando tarefas. Essa segunda fase ensina o modelo a conectar suas previsões a ações concretas.
Essa abordagem resolve o dilema dos dados: usa os dados abundantes e baratos (observação) para 99% do aprendizado e os dados caros e escassos (interação) apenas para o ajuste final.
A arquitetura preditiva de incorporação conjunta (JEPA)
Para entender o V-JEPA 2, precisamos primeiro entender o "JEPA" (Joint-Embedding Predictive Architecture). Ao contrário dos modelos generativos que tentam prever o próximo quadro de um vídeo pixel por pixel (o que é computacionalmente caro e pode se concentrar em detalhes irrelevantes, como a textura exata de uma folha), a abordagem JEPA é diferente.
Ela funciona fazendo previsões em um "espaço de representação" abstrato. Pense nisso da seguinte forma:
Imagine mostrar a um modelo um vídeo de uma bola quicando. Em vez de pedir a ele para desenhar o próximo quadro com a bola em sua nova posição, você o mascara, ou seja, esconde uma parte do vídeo (por exemplo, um bloco de tempo e espaço onde a bola estará). O trabalho do modelo não é pintar os pixels ausentes, mas sim prever a representação abstrata desses pixels ausentes. Essa representação é um conjunto de números (um embedding) que captura as características importantes da cena — como a posição, forma e trajetória da bola — ignorando detalhes imprevisíveis e de alta frequência, como a sombra exata ou o reflexo da luz.
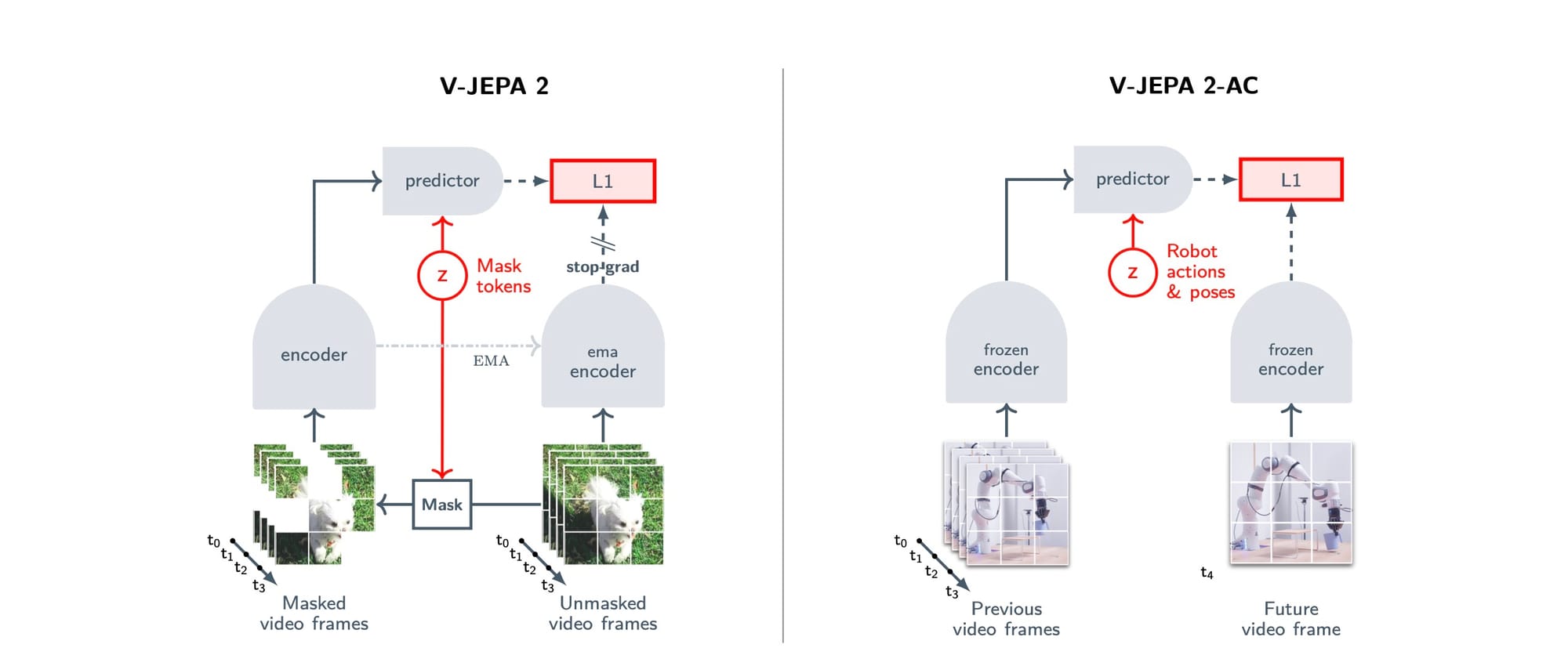
A Figura 2 (Esquerda) do artigo ilustra esse processo. O modelo é composto por um codificador e um preditor. O codificador recebe o vídeo mascarado e o transforma em representações. O preditor, então, usa essas representações para prever as representações das partes que foram escondidas. O objetivo do treinamento é minimizar a diferença (usando uma perda L1) entre a previsão e a representação real da parte oculta, que é calculada por uma cópia do codificador (chamada de codificador EMA, que é atualizada mais lentamente para estabilizar o treinamento).
Após essa fase de pré-treinamento, temos o V-JEPA 2: um codificador de vídeo extremamente poderoso que entende a dinâmica do mundo.
Agora, para torná-lo útil para robótica, entra em cena o V-JEPA 2-AC (Action-Conditioned). Nesta etapa, o codificador do V-JEPA 2 é "congelado" — seus pesos não são mais alterados. Um novo preditor, condicionado à ação, é treinado sobre ele. Esse novo preditor aprende a responder à seguinte pergunta: "Se eu estou neste estado (representado pelo codificador) e executo esta ação (por exemplo, mover o braço do robô 5 cm para a frente), qual será a representação do próximo estado?"
Essa fase utiliza as 62 horas de dados de robôs do dataset Droid, que contém trajetórias de um braço robótico Franka Emika. O modelo aprende a prever o futuro em seu espaço de representação latente, condicionado às ações e aos estados proprioceptivos do robô (como a posição do efetuador final).
Os ingredientes da escala
Uma das contribuições mais importantes do artigo do V-JEPA 2 é a "receita de escalonamento". Os pesquisadores detalham metodicamente os quatro ingredientes que, combinados, levaram a um salto significativo no desempenho. Para qualquer engenheiro de software ou ML, esses insights são ouro puro.
A Figura 3 do artigo resume o impacto de cada ingrediente, partindo de uma linha de base (o V-JEPA 1) e adicionando cada melhoria.
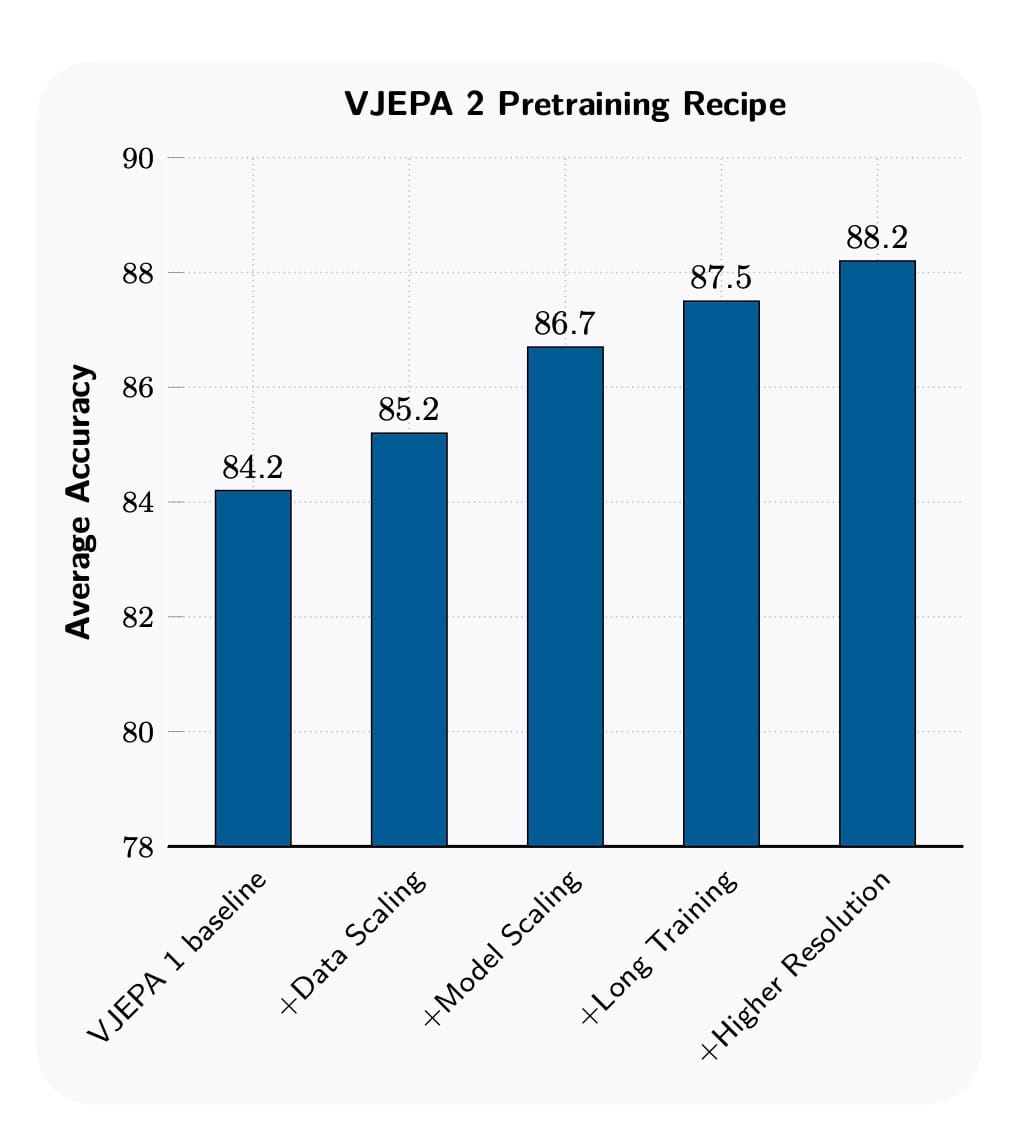
- Escala de dados (+1.0 ponto): A primeira e mais óbvia melhoria foi aumentar massivamente o conjunto de dados. Eles passaram de 2 milhões de vídeos para 22 milhões, combinando fontes públicas como Kinetics (vídeos de ação), HowTo100M (tutoriais) e uma grande coleção de vídeos do YouTube (YT-Temporal-1B). Um detalhe crucial foi a curadoria. Dados brutos da internet podem ser ruidosos (desenhos animados, clipart). Eles usaram um pipeline de curadoria para filtrar e reequilibrar os dados, o que por si só melhorou o desempenho em 1.4 pontos.
- Escala do modelo (+1.5 ponto): O tamanho importa. Eles escalaram a arquitetura do codificador de um ViT-L (Vision Transformer-Large) com 300 milhões de parâmetros para um ViT-g (gigante) com mais de 1 bilhão de parâmetros. Modelos maiores têm mais capacidade de absorver os padrões de conjuntos de dados massivos. Aprenda sobre Transformers neste artigo.
- Treinamento mais longo (+0.8 ponto): Aumentar o número de iterações de treinamento de 90 mil para 252 mil permitiu que o modelo aproveitasse melhor o conjunto de dados expandido. Eles também adotaram um cronograma de taxa de aprendizado do tipo "warmup-constant-decay", que simplifica o ajuste de hiperparâmetros e torna mais eficiente explorar execuções de treinamento longas.
- Resolução mais alta (+0.7 ponto): Processar vídeos mais longos e com maior resolução espacial melhora o desempenho, mas aumenta drasticamente o custo computacional. A solução engenhosa foi um treinamento de resolução progressiva. A maior parte do treinamento (fases de aquecimento e constante) foi feita com clipes de baixa resolução (16 quadros, 256x256 pixels). Apenas na fase final de "cooldown" (quando a taxa de aprendizado diminui) é que eles aumentaram a resolução e a duração dos clipes (até 64 quadros, 384x384). Essa técnica proporcionou uma aceleração de até 8x no tempo de treinamento, tornando viável treinar modelos de alta resolução.
As 3 habilidades do V-JEPA 2: entender, prever e planejar
Com essa poderosa base, o V-JEPA 2 demonstrou capacidades de ponta em três áreas principais.
1. Entendimento
Para testar se o modelo realmente "entende" o que está vendo, os pesquisadores o avaliaram em duas frentes: classificação e perguntas e respostas em vídeo (Video QA).
- Classificação baseada em sonda: Eles congelaram o codificador do V-JEPA 2 e treinaram uma pequena "sonda" (um classificador simples) sobre suas representações para tarefas de classificação de vídeo. O V-JEPA 2 se destacou especialmente em tarefas que exigem compreensão de movimento, como o benchmark Something-Something v2, alcançando uma precisão de 77.3% (top-1), superando modelos anteriores projetados especificamente para a tarefa.
- Video question-answering (Video QA): Em um dos resultados mais impressionantes, eles alinharam o codificador V-JEPA 2 a um Large Language Model (LLM) para criar um modelo multimodal capaz de responder a perguntas sobre vídeos. Notavelmente, o V-JEPA 2 foi pré-treinado sem qualquer supervisão de linguagem (sem pares de vídeo-texto), ao contrário da maioria dos codificadores visuais usados em MLLMs, como o CLIP. Mesmo assim, após o alinhamento, o modelo alcançou desempenho de ponta em múltiplos benchmarks, como 84.0 no Perception Test e 76.9 no TempCompass, superando outros modelos na classe de 8 bilhões de parâmetros.
2. Previsão
A capacidade de antecipar o futuro é uma marca da inteligência. O V-JEPA 2 foi testado no benchmark Epic-Kitchens-100, onde o objetivo é prever a próxima ação de uma pessoa em uma cozinha a partir de um clipe de vídeo.
O modelo alcançou um desempenho de última geração, com um recall@5 de 39.7%, o que representa uma melhoria relativa de 44% sobre o melhor modelo anterior. Isso demonstra que as representações aprendidas pelo V-JEPA 2 contêm informações preditivas ricas sobre intenções e ações humanas.
3. Planejamento
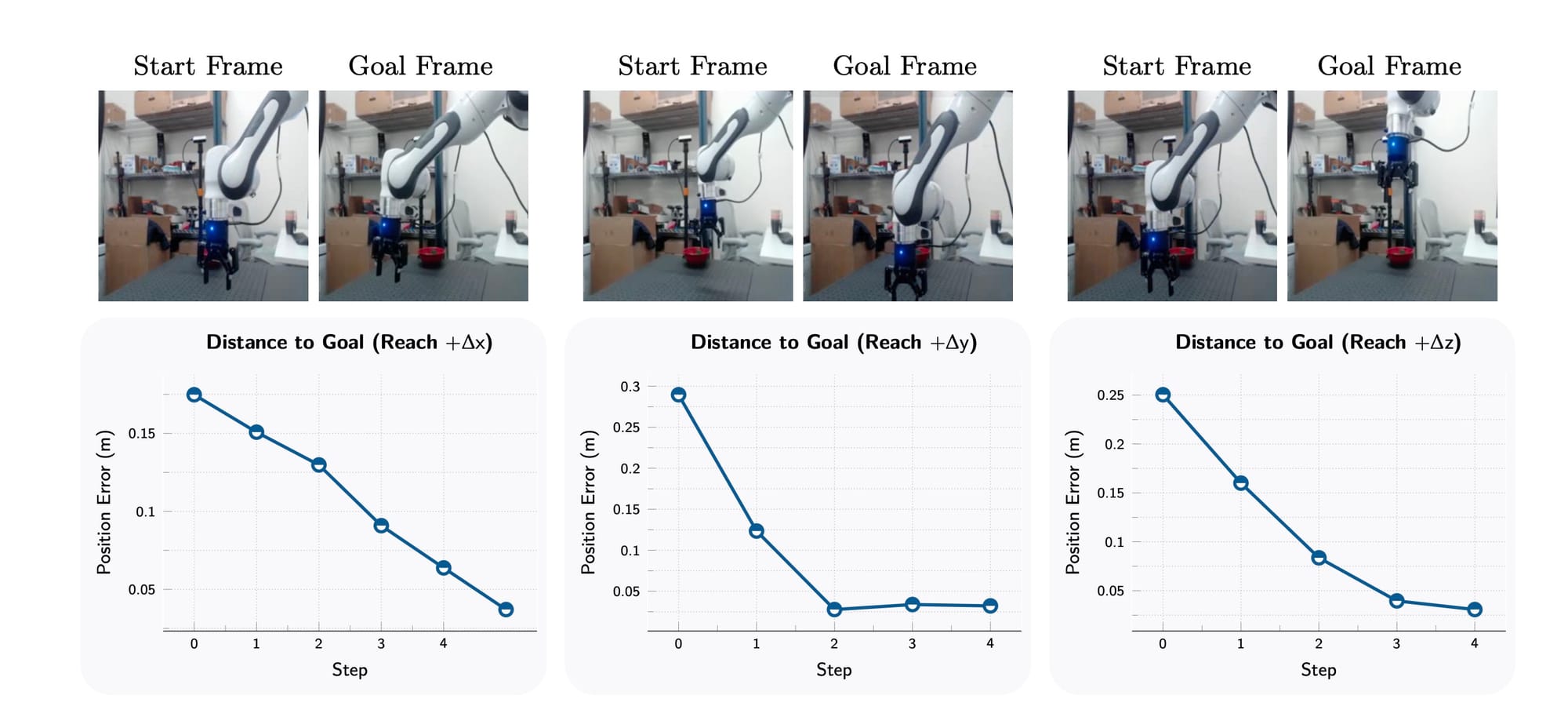
É aqui que a teoria encontra a prática de forma mais espetacular. Usando o modelo V-JEPA 2-AC, a equipe o implantou em robôs Franka reais em dois laboratórios diferentes, ambientes que o modelo nunca tinha visto antes. A implantação foi zero-shot, o que significa que não houve coleta de dados adicionais ou treinamento específico para as tarefas nesses novos ambientes.
O robô executa tarefas usando uma técnica chamada Controle Preditivo de Modelo (MPC), ilustrada na Figura 7.
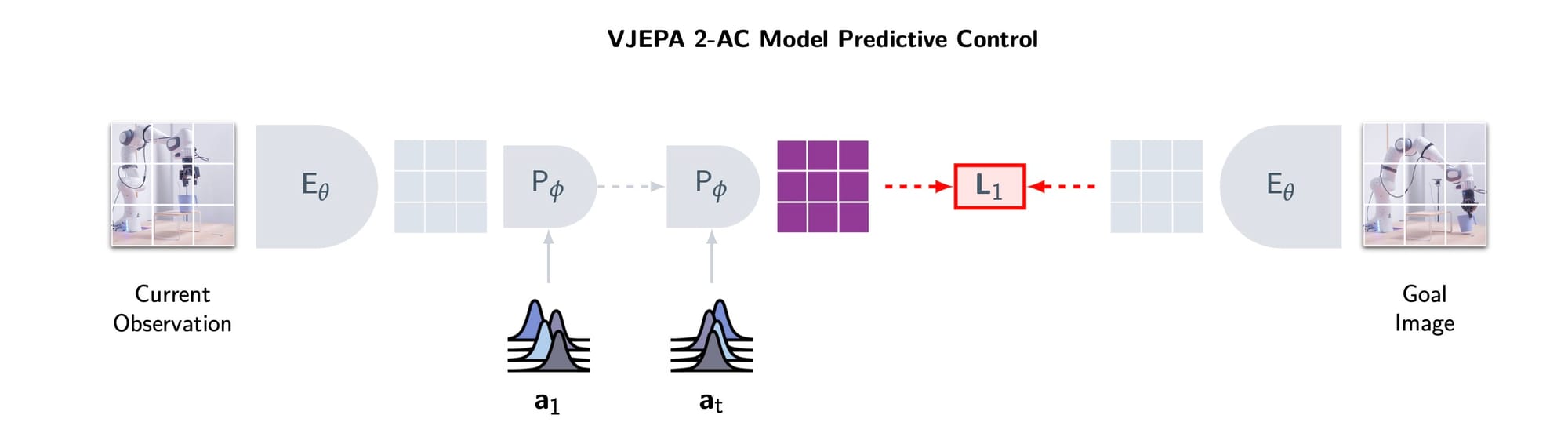
O processo é o seguinte:
- O robô recebe uma imagem do objetivo (por exemplo, a imagem de uma lata em um local específico).
- O V-JEPA 2-AC "imagina" várias sequências de ações futuras. Para cada sequência, ele prevê a representação do estado resultante.
- Ele calcula a "energia" ou o erro (distância L1) entre cada futuro imaginado e a representação da imagem do objetivo.
- Ele seleciona a sequência de ações que minimiza esse erro.
- O robô executa a primeira ação dessa sequência.
- Ele observa o novo estado e repete todo o processo.
Usando essa abordagem, os robôs foram capazes de realizar com sucesso tarefas de manipulação como alcançar, pegar e "pegar e colocar" objetos que nunca tinham visto antes, em ambientes desordenados. As Figuras 8 e 10 do artigo mostram qualitativamente o sucesso dessas tarefas, com o robô se aproximando monotonicamente de seus objetivos.

Análise crítica: V-JEPA 2 vs. o Mundo
O V-JEPA 2 é, sem dúvida, um avanço, mas como ele se compara a outras abordagens de ponta?
vs. Modelos Vision-Language-Action (VLA) como o RT-2 e Octo da Google:
Modelos como o RT-2 aprendem uma política de "ponta a ponta" através da clonagem de comportamento. Eles são treinados em enormes conjuntos de dados de pares (imagem, texto, ação) para aprender a mapear diretamente uma observação e um comando de linguagem para uma ação de robô.
- Vantagem do V-JEPA 2: Flexibilidade e eficiência de dados. Como o V-JEPA 2 aprende um modelo do mundo, ele pode planejar em tempo de inferência para encontrar soluções para problemas que talvez não estivessem explicitamente nos dados de treinamento. Ele pode raciocinar sobre as consequências de suas ações. Além disso, ele pode aprender com dados de interação "ruins" ou com falhas, algo que a clonagem de comportamento geralmente não pode fazer.
- Vantagem dos VLAs: Simplicidade e reatividade. Por serem políticas diretas, a inferência é muito rápida — eles não precisam passar por um processo de planejamento computacionalmente intensivo a cada passo.
vs. World Models Generativos como o Genie (Google) e o Cosmos (Nvidia):
Esses modelos também são "world models", mas funcionam gerando os próximos quadros de vídeo pixel por pixel.
- Vantagem do V-JEPA 2: Eficiência computacional. Prever em um espaço de representação abstrato é muito mais barato do que gerar um vídeo de alta fidelidade. O próprio artigo do V-JEPA 2 faz uma comparação direta com o Cosmos para planejamento. Para calcular uma única ação, o V-JEPA 2-AC levou 16 segundos, enquanto o Cosmos levou 4 minutos. Isso torna o V-JEPA 2 muito mais prático para controle de robôs em tempo real. Além disso, ao focar em representações, ele evita desperdiçar capacidade do modelo em detalhes visualmente irrelevantes.
Limitações e o futuro
A equipe do Meta é transparente sobre as limitações do modelo, que apontam para futuras áreas de pesquisa:
- Sensibilidade à posição da câmera: O modelo atualmente infere implicitamente o sistema de coordenadas da câmera a partir da visão, o que o torna sensível à sua posição. Na prática, a equipe teve que encontrar manualmente uma posição de câmera que funcionasse bem.
- Planejamento de longo horizonte: O planejamento atual é eficaz para tarefas de curto prazo. Para tarefas complexas de longo horizonte (como montar um móvel) sem sub-objetivos explícitos, o acúmulo de erros nas previsões e o espaço de busca exponencial tornam-se um problema.
- Objetivos visuais: O sistema atualmente depende de imagens de objetivo para definir as tarefas. Um passo futuro crucial é permitir que os objetivos sejam especificados de forma mais natural, como através da linguagem ("pegue a lata vermelha de cima da mesa").
Conclusão
O V-JEPA 2 é mais do que apenas um modelo com pontuações altas em benchmarks. É a demonstração de uma filosofia: que a base para uma IA verdadeiramente inteligente e capaz de agir no mundo físico pode ser construída a partir da observação passiva em grande escala, com apenas uma pitada de dados de interação para conectá-la à realidade.
Ao separar o aprendizado da representação do mundo do aprendizado da política de ação e ao favorecer a previsão em um espaço latente em vez do espaço de pixels, o V-JEPA 2 apresenta um caminho que parece ser mais escalável, eficiente em termos de dados e computacionalmente mais viável para o controle robótico no mundo real. Ele representa um passo significativo em direção a um futuro onde os robôs não apenas executam tarefas pré-programadas, mas entendem, se adaptam e agem de forma inteligente em nosso mundo complexo e dinâmico.
Comments