
O que são Transformers? Uma introdução à base da IA
AIEntenda de uma vez por todas, de forma simples, a tecnologia por trás da Inteligência Artificial: Os Transformers.

Resolvi fazer esse artigo para ser um conteúdo de apoio sobre Transformers. Tem vários artigos que falam sobre isso que quero explorar aqui no blog, então achei melhor explicar com detalhes fazendo este conteúdo introdutório. E não, eu não tô falando dos robôs gigantes que viram carros e caminhões. Embora, pensando bem, a revolução que esses Transformers causaram na inteligência artificial seja tão impressionante quanto.
Sabe quando você conversa com o ChatGPT e fica de queixo caído com a resposta? Ou quando o Google completa sua busca antes mesmo de você terminar de digitar? Ou quando o tradutor online transforma um texto em chinês para um português perfeito em um piscar de olhos? Pois é. Por trás de quase toda essa mágica moderna, existe um Transformer trabalhando a todo vapor.
Mas o que é um Transformer?
Se você já tentou pesquisar sobre isso, provavelmente se deparou com um monte de diagramas complexos, matemática que dá dor de cabeça e termos como "Multi-Head Attention" e "Positional Encoding". A ideia aqui é fazer o contrário. Vamos desmistificar tudo isso.
Quero que, ao final deste artigo, você não só entenda o que é um Transformer, mas também consiga explicar a ideia principal para um amigo em uma mesa de bar. Prometo que vou usar o mínimo de jargão possível e o máximo de analogias do dia a dia.
A viagem no tempo: Como a IA tentava entender a linguagem (e falhava miseravelmente)
Antes de entendermos por que os Transformers é a coisa mais fantástica que tem, precisamos dar uma olhadinha no passado. Como as máquinas tentavam entender a gente antes dessa revolução toda?
Imagine que você tem a tarefa de ler "O Senhor dos Anéis". Um livro gigante, com milhares de personagens, lugares e eventos. Agora, imagine que você só pode ler uma palavra de cada vez. E pior: para entender o significado da palavra que você está lendo agora, você precisa se lembrar de todas as palavras que leu antes, na ordem exata.
Parece um pesadelo, né? Pois era mais ou menos assim que os modelos de IA mais antigos, como as RNNs (Redes Neurais Recorrentes) e as LSTMs (Long Short-Term Memory), funcionavam.
O problema da memória de peixinho dourado
As RNNs foram uma primeira tentativa genial. A ideia era simples: a rede lê uma palavra, processa essa informação e "passa" um resumo do que entendeu para a próxima etapa, onde lerá a próxima palavra. Esse "resumo" é uma espécie de memória.
Vamos pegar uma frase simples: "O gato sentou no tapete".
- A RNN lê "O".
- Processa "O" e guarda uma memória.
- Lê "gato". Ela combina a informação de "gato" com a memória de "O".
- Processa isso, gera uma nova memória e passa para a frente.
- Lê "sentou", combina com a memória de "O gato", e assim por diante.
Isso funciona bem para frases curtas. O problema é que essa memória era muito, mas muito curta. A cada nova palavra, a memória antiga ia se "dissolvendo". É o famoso "problema do gradiente descendente". Em termos simples: a informação do início da frase se perdia completamente no final.
Imagine a frase: "Eu cresci na França, viajei por toda a Europa quando jovem, mas hoje, depois de morar em vários países, posso dizer que minha língua fluente é o..."
Para a máquina prever a palavra "francês", ela precisa se lembrar da palavra "França" lá no comecinho da frase. Para uma RNN simples, essa informação já virou pó cósmico. Ela provavelmente se lembraria de "países" ou "língua" e poderia chutar qualquer idioma.
A tentativa de turbinar a memória: as LSTMs
Para resolver esse problema, surgiram as LSTMs. Pense nelas como uma RNN com superpoderes. Elas tinham um sistema mais sofisticado de "portões" (gates) que permitia que a rede decidisse o que era importante guardar na memória de longo prazo e o que era lixo para ser descartado.
Uma LSTM era como um estudante com um caderno e canetas marca-texto. Ela podia ler uma informação e pensar: "Hmm, 'França' parece importante, vou sublinhar isso aqui no meu caderno de memória de longo prazo". E mais para frente ela poderia "esquecer" informações menos relevantes, como "viajei por toda a Europa".
Foi um avanço gigantesco! As LSTMs dominaram o processamento de linguagem natural por anos e tornaram muitas aplicações, como traduções automáticas melhores, possíveis.
Mas... ainda havia um problema fundamental.
O grande gargalo era a fila indiana
Tanto as RNNs quanto as LSTMs eram sequenciais. Elas precisavam processar a primeira palavra para depois processar a segunda, e a segunda para processar a terceira... Era como uma fila indiana. Não importava o quão potente fosse o seu computador, você não podia processar o meio da frase sem ter passado pelo começo.
Isso tornava o treinamento desses modelos extremamente lento. Treinar uma IA em uma quantidade massiva de textos (como, sei lá, a internet inteira) era praticamente inviável. Além disso, mesmo com a memória turbinada das LSTMs, as relações entre palavras muito distantes ainda eram difíceis de capturar.
O mundo precisava de uma nova abordagem. Uma forma de olhar para a frase inteira de uma vez só, entendendo como cada palavra se relaciona com todas as outras, sem precisar seguir uma fila.
E então, em 2017, um grupo de pesquisadores do Google publicou um artigo com um título quase arrogante de tão genial: "Attention is all you need". E eles não estavam brincando.

O big bang da IA: esqueça a fila, preste atenção!
Imagine que, em vez de ler "O Senhor dos Anéis" palavra por palavra, você pudesse colocar o livro inteiro aberto em uma mesa gigante. Você poderia olhar para a palavra "Frodo" no último capítulo e, instantaneamente, conectar essa palavra com todas as outras vezes que "Frodo" apareceu no livro, com a palavra "Anel", com "Sam", com "Mordor", tudo ao mesmo tempo.
Você não estaria mais preso a uma sequência. Você estaria olhando para o todo, entendendo o contexto geral e as conexões de uma só vez.
Essa é a ideia central por trás dos Transformers. Eles se livraram completamente da necessidade de processar as coisas em fila (adeus, RNNs!) e introduziram um mecanismo chamado atenção (attention).
O que é "Atenção"?
No nosso dia a dia, a gente usa "atenção" o tempo todo. Se eu digo a frase: "O jogador chutou a bola com força e marcou o gol", o seu cérebro, sem que você perceba, faz conexões.
- "Jogador" está ligado a "chutou" e "marcou".
- "Bola" está intimamente ligada a "chutou".
- "Gol" é o resultado de "marcou".
Você não precisa processar a frase sequencialmente para saber que quem marcou o gol foi o jogador, e não a bola. O seu cérebro dá "pesos" de importância diferentes para cada palavra quando você tenta entender o contexto de outra. Ao focar na palavra "chutou", as palavras "jogador" e "bola" brilham mais forte na sua mente do que as palavras "com" ou "e".
O mecanismo de self-attention (auto-atenção) dos Transformers tenta imitar exatamente isso. Ele permite que, para cada palavra em uma frase, o modelo olhe para todas as outras palavras na mesma frase e decida: "Quais dessas outras palavras são mais importantes para me ajudar a entender o significado desta palavra aqui?".
Isso resolve os dois grandes problemas de uma vez só:
- O problema da distância: Não importa se as palavras estão a duas ou a duzentas palavras de distância. Se "França" no início da frase é relevante para "língua" no final, o mecanismo de atenção pode criar uma conexão direta e forte entre elas. Adeus, memória de peixinho dourado!
- O problema da fila: Como a conexão é feita entre todas as palavras ao mesmo tempo, o cálculo pode ser feito em paralelo. Em vez de uma fila de pão, temos um supermercado com dezenas de caixas abertos. Isso significa que podemos usar o poder das GPUs (as placas de vídeo, que são ótimas em fazer muitos cálculos ao mesmo tempo) para treinar modelos gigantescos em uma velocidade absurdamente mais rápida.
Foi essa capacidade de paralelização que abriu as portas para modelos como o GPT-3 e o BERT serem treinados em praticamente toda a internet.
Mergulhando na matrix: como a "auto-atenção" funciona na prática
Ok, a ideia de "prestar atenção" é legal e intuitiva. Mas como um computador faz isso? Como ele "decide" o que é importante? Agora vamos entrar na parte um pouquinho mais técnica, mas prometo manter a simplicidade.
Imagine que cada palavra na sua frase é uma pessoa em uma festa de networking. Cada pessoa (palavra) quer se descrever e entender melhor as outras. Para fazer isso, cada pessoa cria três cartões de visita:
- A query (a pergunta): É o cartão que diz "Ei, eu sou a palavra 'chutou'. Estou procurando por quem chuta e o que é chutado." É basicamente o que a palavra está buscando.
- A key (a chave): É o cartão que diz "Olá, eu sou a palavra 'jogador'. Minha especialidade é 'realizar ações em um esporte'". É a "etiqueta" da palavra, o que ela representa.
- The value (o valor): É o cartão que contém a informação real, a substância da palavra. "Eu sou a palavra 'jogador', um ser humano que pratica esportes".
Agora, a palavra "chutou" (a nossa query) vai andar pela festa. Ela pega seu cartão de Pergunta e o compara com o cartão de Chave de todas as outras palavras (incluindo ela mesma).
- "chutou" (Query) vs. "jogador" (Key): A pergunta "quem chuta?" combina perfeitamente com a chave "eu realizo ações". MATCH! A conexão aqui será forte.
- "chutou" (Query) vs. "bola" (Key): A pergunta "o que é chutado?" combina perfeitamente com a chave "eu sou um objeto usado em esportes". MATCH! Outra conexão forte.
- "chutou" (Query) vs. "e" (Key): A pergunta "quem chuta?" não tem nada a ver com a chave "eu sou uma conjunção que liga coisas". A conexão aqui será fraquíssima, quase zero.
Após comparar sua Pergunta com todas as Chaves, a palavra "chutou" calcula uma "pontuação de atenção" para cada outra palavra. A pontuação será alta para "jogador" e "bola", e minúscula para "e", "com", "a".
E agora vem o pulo do gato. A palavra "chutou" vai criar uma nova representação de si mesma, um novo significado contextualizado. E ela faz isso pegando os cartões de Valor de todas as outras palavras, mas ponderados pela pontuação de atenção.
É como se ela dissesse:
"Ok, a informação (Valor) de 'jogador' é super importante pra mim, vou pegar 100% dela. A informação (Valor) de 'bola' também é muito importante, vou pegar 98% dela. A informação (Valor) de 'e' não me interessa nem um pouco, vou pegar 0.01% dela."
Ela soma todos esses pedacinhos de informação (Valores) e cria uma nova versão de si mesma: um "chutou" que "sabe" que foi realizado por um "jogador" e que o alvo foi uma "bola".
E o mais incrível é que TODAS as palavras na frase fazem isso AO MESMO TEMPO!
A palavra "jogador" está fazendo seu próprio cálculo de atenção para entender que sua ação é "chutar". A palavra "bola" está fazendo o seu para entender que a ação sofrida foi um "chute". O resultado é que, após uma rodada de Self-Attention, cada palavra não é mais apenas uma palavra isolada; ela se torna um vetor de informação riquíssimo, já "impregnado" com o contexto de toda a frase.
É como se as palavras conversassem entre si para descobrir seus verdadeiros papéis naquela sentença específica. Genial, né?
Por que ter apenas uma cabeça se você pode ter várias? (Multi-Head Attention)
Os criadores dos Transformers pensaram: "Ok, esse mecanismo de atenção é ótimo. Mas e se uma palavra precisar prestar atenção a coisas diferentes ao mesmo tempo?".
Na nossa frase, "O jogador chutou a bola com força e marcou o gol", a palavra "jogador" pode ter diferentes tipos de relações:
- Relação de agente-ação: Quem chutou? O jogador.
- Relação sintática: "jogador" é o sujeito da frase.
- Relação semântica geral: "jogador" pertence ao campo semântico de "esporte", junto com "bola" e "gol".
Limitar a atenção a um único tipo de cálculo (um único conjunto de Query, Key e Value) poderia ser restritivo. A solução? Multi-Head Attention (Atenção de Múltiplas Cabeças).
Pense nisso como formar vários comitês de especialistas para analisar a mesma frase.
- A "cabeça" 1 (o comitê de gramática): Vai focar em identificar sujeitos, verbos, objetos. Ela vai criar uma forte conexão entre "jogador" (sujeito) e "chutou" (verbo).
- A "cabeça" 2 (o comitê de ações): Vai focar em quem fez o quê. Ela vai conectar "jogador" com "chutou" e "marcou".
- A "cabeça" 3 (o comitê de relações de objetos): Vai focar em como os objetos interagem. Ela vai conectar "chutou" com "bola".
- ...e assim por diante, com 8, 12, ou até mais "cabeças".
Cada "cabeça" faz seu próprio cálculo de atenção de forma independente, com seus próprios cartões de Query, Key e Value. Cada uma aprende a focar em um tipo diferente de relação entre as palavras.
No final, as saídas de todas essas cabeças são juntadas e processadas. É como se, para entender a palavra "jogador", o modelo recebesse o relatório do comitê de gramática, o relatório do comitê de ações, o do comitê de objetos, etc. O resultado final é uma compreensão da palavra que é incrivelmente rica e multifacetada.
O GPS das palavras: se tudo é ao mesmo tempo, como saber a ordem?
Temos um problema. Se o Transformer olha para todas as palavras de uma vez, como ele sabe a ordem delas?
Para um modelo sequencial como uma RNN, a ordem era a própria base do seu funcionamento. Mas para um Transformer, as frases "O cão mordeu o homem" e "O homem mordeu o cão" pareceriam exatamente iguais, pois contêm as mesmas palavras. O mecanismo de atenção veria as mesmas conexões ("homem" e "mordeu", "cão" e "mordeu"), mas não saberia quem fez o quê a quem. E todos sabemos que a ordem, nesse caso, importa (e muito!).
É aqui que entra o último ingrediente mágico principal: o Positional Encoding (Codificação Posicional).
A solução é surpreendentemente simples e elegante. Antes de entregar as palavras para o mecanismo de atenção, o modelo "injeta" em cada palavra uma pequena informação extra, um pedacinho de código matemático que indica sua posição na frase.
Pense nisso como dar um número de RG para cada palavra. A primeira palavra ganha o RG "Posição 1", a segunda ganha o RG "Posição 2", e assim por diante. Só que, em vez de um número simples, é um vetor matemático complexo (criado com funções de seno e cosseno, para os curiosos).
Esse "RG posicional" é somado à representação da palavra. Assim, a palavra "homem" na posição 2 se torna ligeiramente diferente da palavra "homem" na posição 4. O mecanismo de atenção, ao fazer seus cálculos, agora consegue não só ver o conteúdo da palavra, mas também sua localização. Ele pode aprender regras como "se uma palavra na Posição X é um substantivo e uma palavra na Posição Y (logo depois) é um verbo, então é provável que o substantivo seja o sujeito do verbo".
É o GPS que faltava. Ele garante que, mesmo processando tudo em paralelo, o modelo nunca perca a noção da estrutura e da ordem originais da frase.
Montando o quebra-cabeça: a arquitetura completa
Ok, já vimos as peças principais:
- Self-Attention: Para que as palavras se entendam.
- Multi-Head Attention: Para entender as palavras de várias perspectivas diferentes.
- Positional Encoding: Para não perder a ordem das coisas.
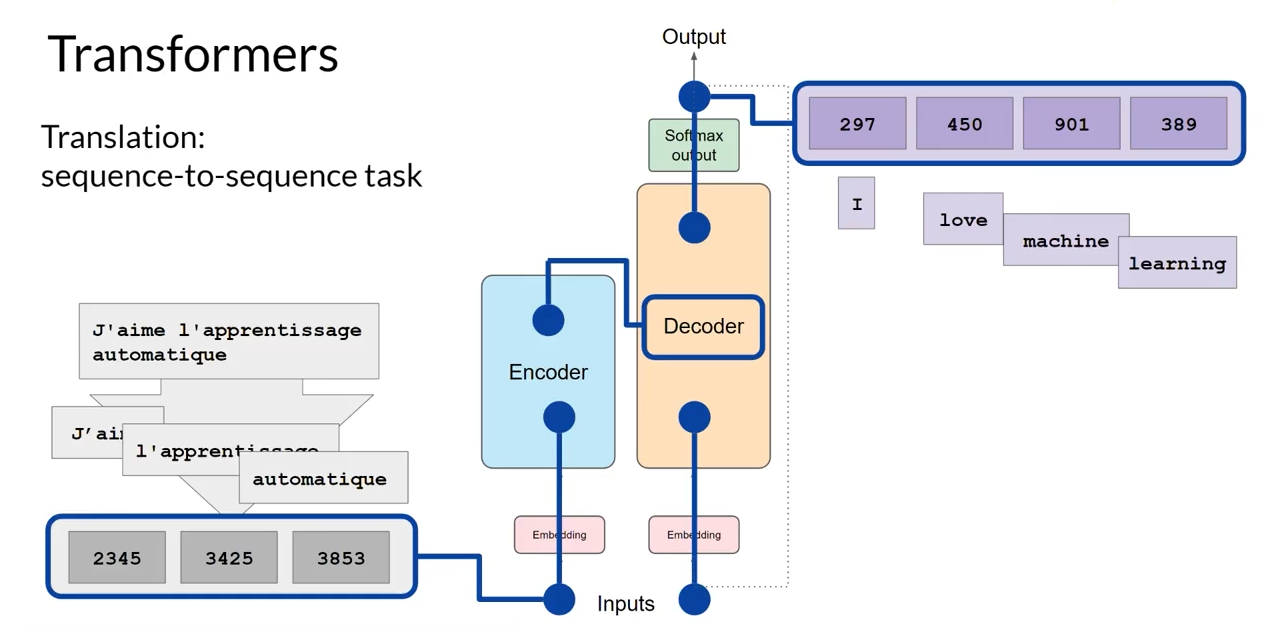
A arquitetura completa de um Transformer, como descrita no artigo original, usa esses blocos em uma estrutura de Encoder-Decoder (Codificador-Decodificador).
Pense em um tradutor humano profissional. O processo dele tem duas fases:
- Fase de entendimento (codificação): Ele lê a frase inteira no idioma original (ex: inglês). Ele não começa a traduzir imediatamente. Primeiro, ele lê, relê, e constrói uma representação mental abstrata do significado completo daquela frase. Ele entende as nuances, as intenções, o contexto. Essa é a função do Encoder.
- Fase de geração (decodificação): Com essa ideia abstrata na cabeça, ele começa a escrever a frase no idioma de destino (ex: português). Ele gera uma palavra de cada vez, mas a cada palavra que escreve, ele consulta aquela "ideia abstrata" que ele formou para garantir que a tradução seja fiel, e também olha para as palavras que ele já escreveu em português para garantir que a frase faça sentido. Essa é a função do Decoder.
O Transformer faz exatamente isso.
- O Encoder é uma pilha de blocos (geralmente 6 ou 12) que contém Multi-Head Attention e outras camadas. Sua única função é receber a frase de entrada (em inglês, por exemplo) e, através de sucessivas camadas de auto-atenção, gerar uma representação numérica riquíssima que captura todo o significado e contexto daquela frase.
- O Decoder também é uma pilha de blocos. Ele recebe duas coisas: a representação super-rica do Encoder e as palavras que ele já traduziu até agora (em português). Ele então usa seu próprio mecanismo de atenção para decidir qual a próxima palavra a ser gerada, garantindo que a tradução seja coerente e fiel ao original.
Se depois quiser entender sobre o motivo das IAs hoje não serem consideradas inteligentes e como resolver isso, leia este artigo.
A família transformer: BERT, GPT e o resto todo
A arquitetura Encoder-Decoder é poderosa para tarefas de sequência-a-sequência, como tradução ou sumarização. Mas a verdadeira explosão de criatividade veio quando as pessoas perceberam que podiam usar partes dessa arquitetura para outras tarefas.
- Modelos como o BERT (do Google): Perceberam que, para muitas tarefas (como análise de sentimento de uma frase ou responder a uma pergunta sobre um texto), você não precisa gerar um novo texto. Você só precisa entender o texto de entrada da forma mais profunda possível. Então, eles pegaram apenas o Encoder dos Transformers. O BERT (Bidirectional Encoder Representations from Transformers) é, essencialmente, uma máquina de compreensão de texto ultra-potente. Ele lê um texto e gera uma representação numérica incrível para cada palavra, já com todo o contexto "bidirecional" (olhando para a esquerda e para a direita da palavra).
- Modelos como o GPT (da OpenAI): Perceberam que, para tarefas de geração de texto (como escrever um e-mail, criar uma história ou conversar com um humano), o mais importante é saber prever a próxima palavra. Então, eles pegaram apenas o Decoder dos Transformers. O GPT (Generative Pre-trained Transformer) é uma máquina de geração de texto. Você dá a ele um começo de frase ("O melhor filme de todos os tempos é...") e ele usa seu poder de atenção (focando no que já foi escrito) para prever a palavra mais provável a seguir, e depois a próxima, e a próxima, criando textos que parecem ter sido escritos por humanos. Parece, mas não são. E neste artigo eu falo sobre a fraude nos detectores de IA.
Toda a família de IAs generativas que vemos hoje, como o ChatGPT, o Claude, o Llama e tantos outros, são descendentes diretos dessa ideia de usar a parte do Decoder do Transformer.
Conclusão: por que você deveria se importar com tudo isso?
Esse texto ficou um pouco longo, eu sei. Mas se você chegou até aqui, agora você faz parte de um grupo seleto de pessoas que realmente entende o princípio por trás da maior revolução da IA desde... bem, desde sempre.
Os Transformers não são apenas mais um avanço incremental. Eles foram uma mudança de paradigma. Ao resolver os problemas de memória e de processamento sequencial, eles destravaram a capacidade da IA de aprender com a imensa quantidade de dados que nós, humanos, geramos todos os dias.
Hoje, essa tecnologia não está apenas nos chatbots. Ela está:
- Melhorando sua busca no Google: Para entender a intenção por trás do que você digita.
- Gerando legendas para vídeos no YouTube: Entendendo a fala e transcrevendo-a.
- Ajudando a escrever códigos de programação: O GitHub Copilot usa um modelo tipo GPT para sugerir linhas de código.
- Descobrindo novas drogas: Ao analisar as complexas estruturas de proteínas como se fossem frases. Leia isso.
- Criando arte e música: Modelos como o DALL-E e o Midjourney usam a mesma arquitetura para entender texto e gerar imagens.
Nós estamos vivendo em um mundo construído sobre a "Atenção". E o mais bonito de tudo é que a ideia central, como vimos, não é uma matemática impenetrável. É um conceito que todos nós usamos a cada segundo: focar no que é importante para entender o mundo ao nosso redor.
A próxima vez que você se surpreender com a inteligência de uma máquina, lembre-se da festa de networking das palavras, dos comitês de especialistas de múltiplas cabeças e do GPS posicional. Lembre-se que, por baixo de todo o silício e de todos os algoritmos, existe uma ideia elegantemente simples que mudou tudo.
Atenção, afinal, é tudo o que você precisa. 😉
Comments