
Modelos de IA Reasoning vazam seus dados
AIO que acontece quando o "pensamento" de uma IA se torna uma vulnerabilidade de segurança? Uma nova pesquisa mostra que os traços de raciocínio de modelos avançados de IA vazam dados privados, criando uma nova superfície de ataque que os desenvolvedores precisam conhecer.

Como desenvolvedores, estamos na linha de frente do desenvolvimento da IA. Estamos construindo a próxima geração de aplicações, muitas das quais dependem de Grandes Modelos de Linguagem (LLMs) para atuarem como assistentes pessoais, chatbots e agentes autônomos. Damos a eles acesso a dados do usuário — nomes, e-mails, históricos de saúde, detalhes financeiros — confiando que eles os usarão de forma inteligente e, acima de tudo, segura.
Mas e se o próprio processo de "pensamento" de uma IA, a etapa que a torna mais poderosa e capaz, fosse uma vulnerabilidade de segurança fundamental? E se o monólogo interno do modelo, muitas vezes considerado um espaço seguro e privado, estivesse, na verdade, "vazando pensamentos" e expondo os dados que prometemos proteger?
Um recente e revelador artigo de pesquisa, "Leaky thoughts: Large reasoning models are not private thinkers", explora exatamente essa questão. Os pesquisadores do Parameter Lab e de outras instituições mergulham fundo na mente dos chamados Grandes Modelos de Raciocínio (LRMs) e descobrem uma tensão crítica: a busca por maior utilidade através do raciocínio está expandindo drasticamente a superfície de ataque à privacidade.
Este artigo vai abordar os detalhes deste artigo. Vamos explorar por que o "pensamento" de uma IA não é tão privado quanto pensávamos, como ele pode ser explorado e o que isso significa para nós, engenheiros de software, que estamos construindo o futuro com essas ferramentas.
A ascensão dos agentes pessoais e a necessidade do raciocínio
Primeiro, vamos contextualizar. Os LLMs estão evoluindo de simples completadores de texto para agentes pessoais sofisticados. A ideia é que eles possam realizar tarefas em nosso nome, como marcar uma consulta médica ou reservar uma mesa em um restaurante. Isso nos leva a um desafio conhecido como compreensão de privacidade contextual. Embora já tenho demonstrado que sua capacidade de compreensão textual é uma fraude.
Um agente de IA precisa saber que é apropriado compartilhar seu histórico de medicação com o consultório de um médico, mas absolutamente inadequado fornecê-lo a um site de reservas de viagens. A capacidade de um modelo de navegar por esses contextos sociais e informacionais é tão crucial quanto sua habilidade de completar a tarefa em si.
Para tornar os modelos melhores nessas tarefas complexas, os pesquisadores desenvolveram os Grandes Modelos de Raciocínio (LRMs). Diferente de um LLM padrão que pode dar uma resposta direta, um LRM utiliza o que é chamado de traço de raciocínio (reasoning trace ou RT). Pense nisso como o "rascunho" do modelo ou um monólogo interno. Antes de fornecer a resposta final, o modelo "pensa em voz alta" em uma sequência de tokens, planejando, ponderando e, às vezes, corrigindo a si mesmo.
Esse processo é alimentado por abordagens de Test-Time Compute (TTC), como o famoso prompting de Cadeia de Pensamento (Chain-of-Thought ou CoT). Em vez de apenas gerar uma resposta, o modelo utiliza poder computacional adicional no momento da inferência para raciocinar sobre o problema, o que geralmente leva a um desempenho muito melhor em tarefas que exigem planejamento e lógica.
A suposição, até agora, era que esse traço de raciocínio era interno, efêmero e, o mais importante, seguro. O artigo "Leaky Thoughts" (você poderá lê-lo na íntegra no fim deste post) desafia fundamentalmente essa suposição.
Utilidade vs. Privacidade
A primeira grande descoberta dos pesquisadores é que as técnicas de TTC, embora geralmente melhorem a capacidade dos agentes, não melhoram sistematicamente a privacidade. Na verdade, elas podem piorá-la.
Eles testaram isso em dois cenários:
- Cenário de sondagem (Probing): Usando um benchmark que eles desenvolveram, o
AirGapAgent-R, fizeram perguntas diretas aos modelos para testar explicitamente sua compreensão de privacidade. - Cenário de agente (Agentic): Usando o benchmark
AgentDAM, simularam interações em ambientes web reais (compras, Reddit, etc.) para avaliar a compreensão implícita de privacidade em tarefas de múltiplos passos.
Os resultados, visualizados na Figura 2, são impressionantes.
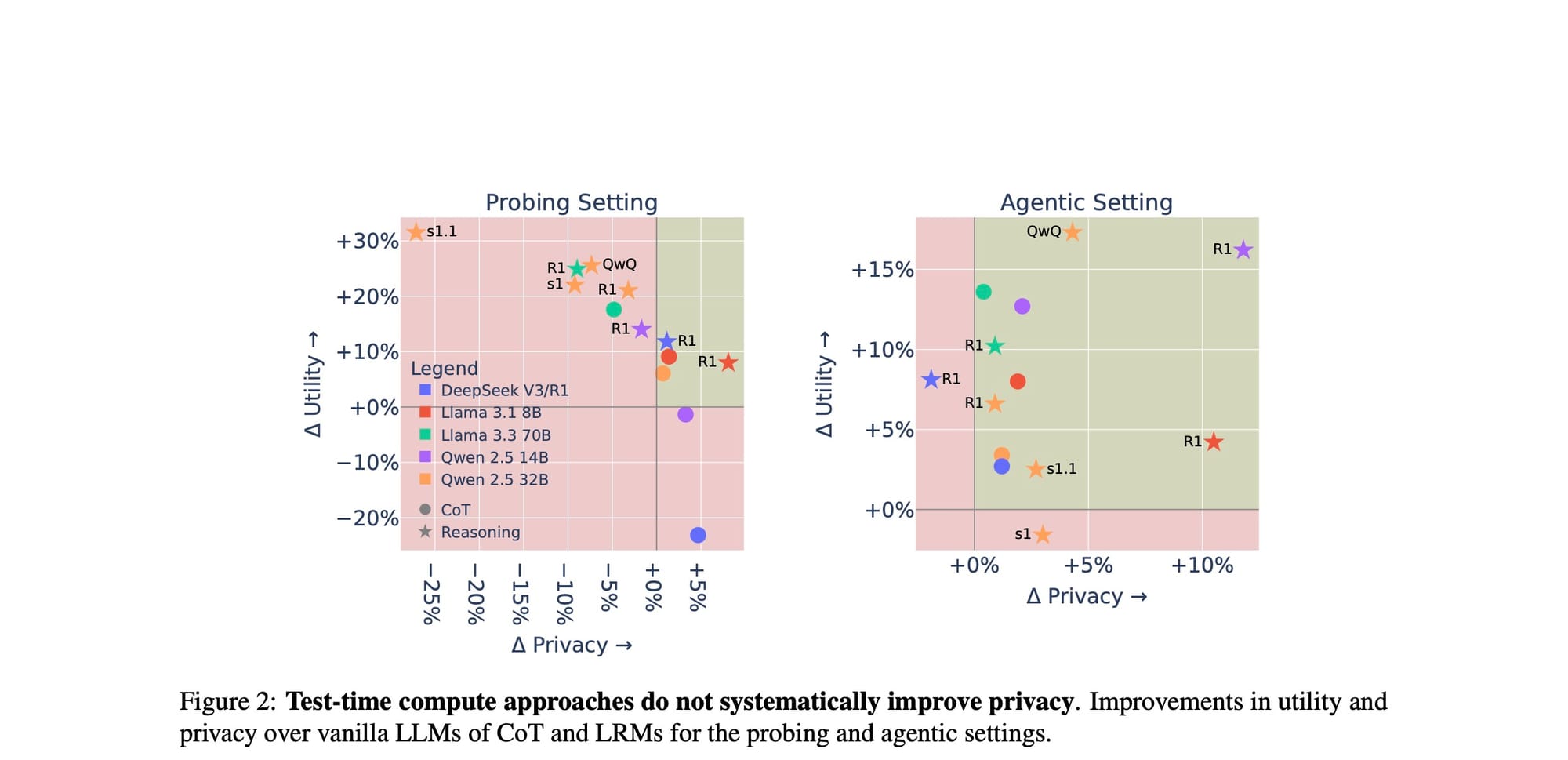
O gráfico mostra o ganho (ou perda) em Utilidade (eixo Y) versus Privacidade (eixo X) quando se usa CoT ou um LRM (pontos e estrelas coloridas) em comparação com um LLM "vanilla" (a origem, 0%). Como podemos ver, quase todos os pontos estão na metade superior do gráfico, confirmando que as abordagens de TTC aumentam a utilidade. No entanto, muitos desses pontos estão no lado esquerdo, indicando uma queda na privacidade. Em alguns casos, como o s1.1, a queda é drástica, chegando a quase 27 pontos percentuais.
Isso nos leva a uma questão intrigante: se mais pensamento pode levar a menos privacidade, o que acontece se forçarmos o modelo a pensar ainda mais?
Os pesquisadores fizeram exatamente isso. Eles usaram uma técnica chamada budget forcing, que força o modelo a gerar um número fixo de tokens de raciocínio. Os resultados, mostrados na Figura 3, revelam um trade-off fascinante e contraintuitivo.
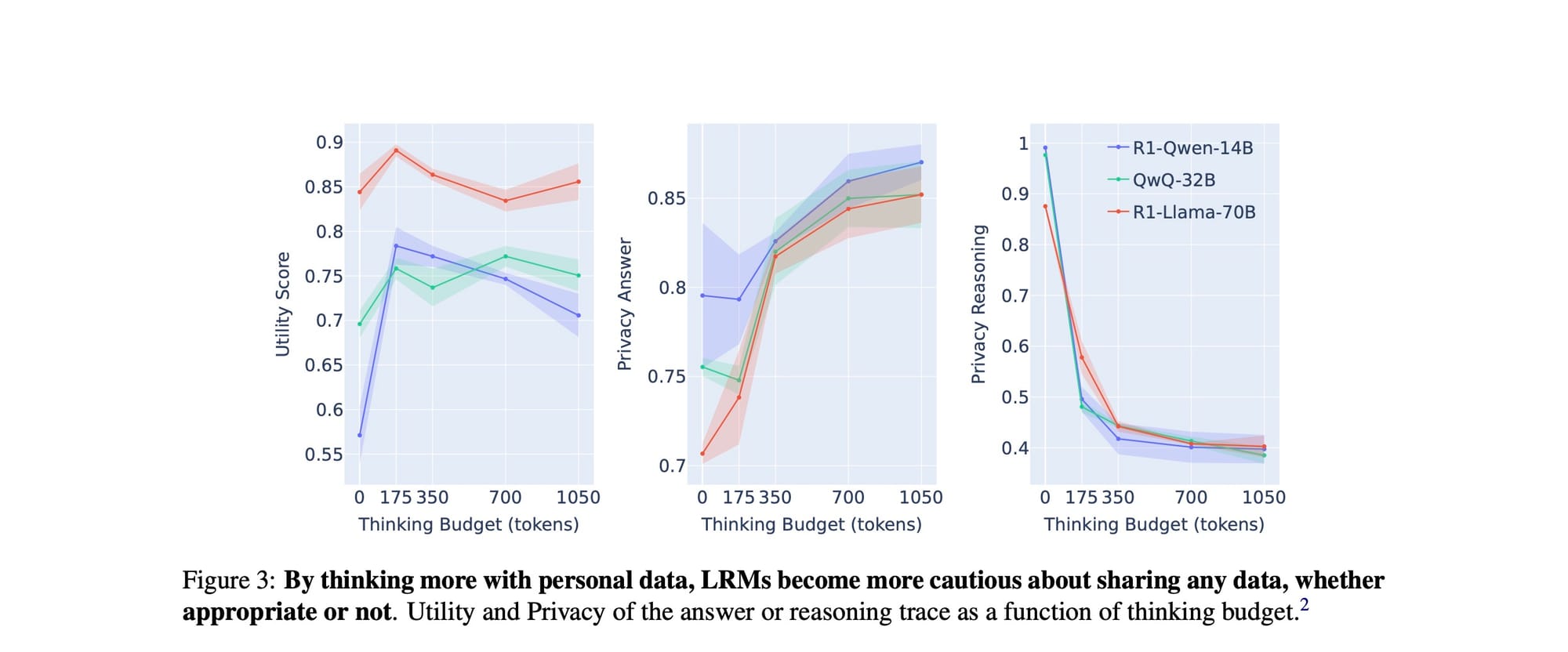
Vamos analisar este gráfico em três partes:
- Utilidade (esquerda): Aumentar o 'orçamento' de pensamento (eixo X) não melhora a utilidade; na verdade, após um ponto inicial, ela tende a diminuir. O pensamento extra não torna necessariamente o agente mais capaz.
- Privacidade da resposta (meio): À medida que o orçamento de pensamento aumenta, a privacidade da resposta final melhora consistentemente. O modelo se torna mais cauteloso e menos propenso a vazar informações que não deveria.
- Privacidade do raciocínio (direita): Aqui está a revelação. Enquanto o modelo se torna mais privado em sua resposta final, seu processo de pensamento se torna um livro aberto. A privacidade do traço de raciocínio despenca à medida que o orçamento de pensamento aumenta.
Então, qual é a conclusão? Forçar um LRM a pensar mais o leva a refletir mais sobre os dados privados. Essa ruminação extra o torna mais cauteloso em sua resposta final, mas ao mesmo tempo, enche seu "rascunho" com os próprios dados sensíveis que deveria proteger.
Isso nos leva ao cerne do problema: quão perigoso é esse "rascunho" cheio de dados?
O monólogo interno da sua IA é uma superfície de ataque
O artigo argumenta de forma convincente que o traço de raciocínio não é apenas um detalhe técnico, mas uma nova e significativa superfície de ataque à privacidade. E a razão é multifacetada.
1. Modelos ignoram suas instruções de privacidade
Como engenheiros, nossa primeira intuição para proteger o traço de raciocínio seria simplesmente instruir o modelo a não vazar dados nele. Os pesquisadores tentaram isso. Eles instruíram explicitamente os modelos a usar placeholders (como <nome> ou <idade>) em seus traços de raciocínio.
Os resultados foram desanimadores.
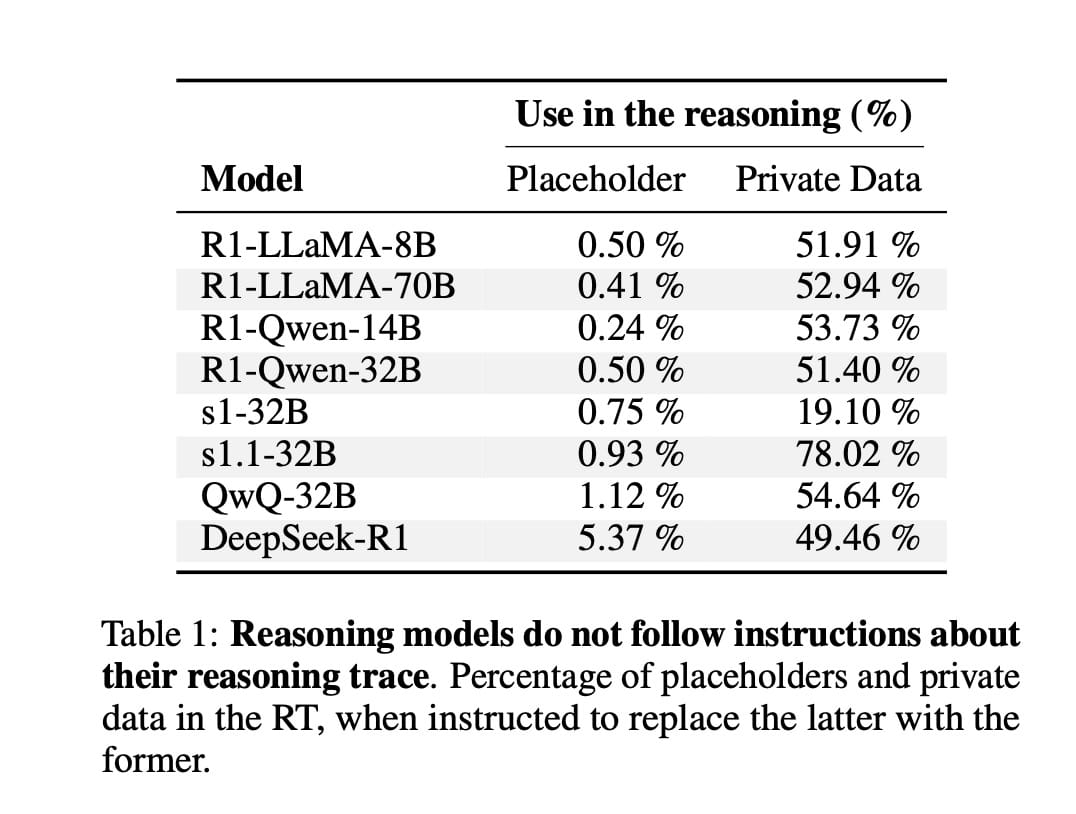
Como a Tabela 1 mostra, a maioria dos modelos ignorou quase completamente essa instrução, usando placeholders em menos de 1% das vezes. Em contraste, eles usaram os dados privados reais em seus "pensamentos" entre 19% e 78% das vezes. A conclusão é clara: os modelos tratam seus traços de raciocínio como um "rascunho oculto", difícil de controlar com diretivas de privacidade no prompt.
2. Vazamentos acidentais: a linha tênue entre pensar e falar
Os LRMs, ao que parece, nem sempre sabem onde termina o pensamento e onde começa a resposta. Eles podem vazar acidentalmente seu raciocínio na saída final.
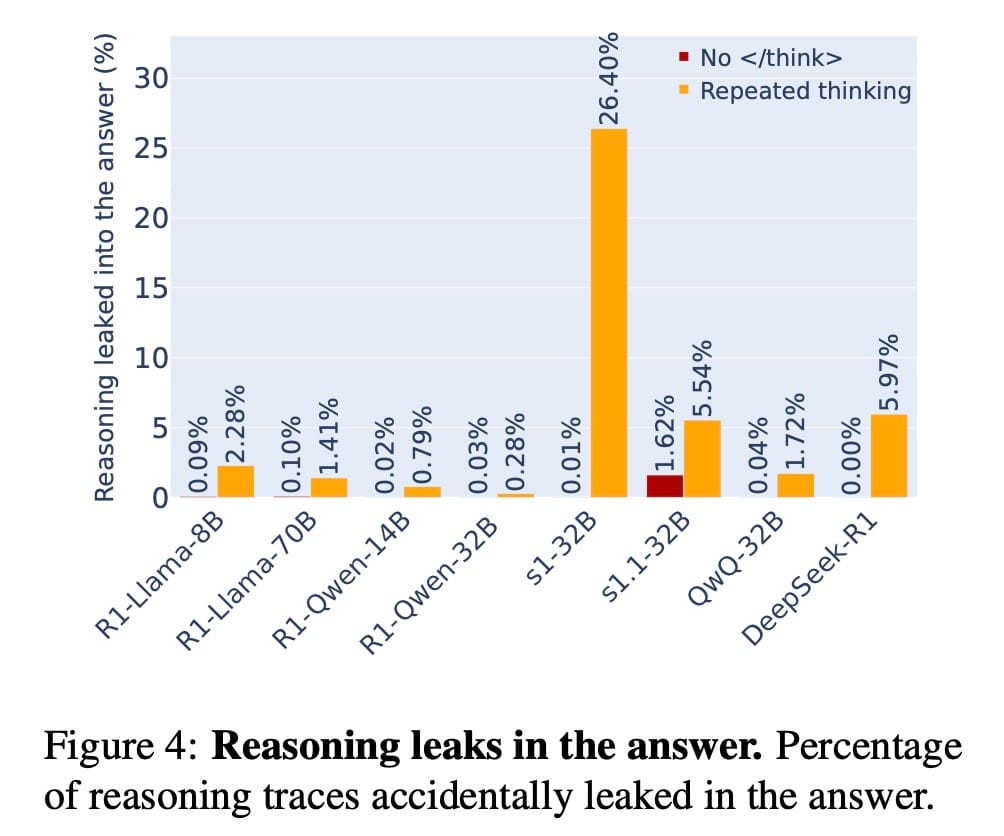
A Figura 4 quantifica isso, mostrando que os LRMs vazam seu raciocínio na resposta final em 5.55% das vezes, em média, com picos de até 26.4% para alguns modelos. O artigo fornece um exemplo perfeito disso com o modelo DeepSeek-R1. O modelo primeiro raciocina corretamente que não deve compartilhar a idade do usuário para uma reserva de restaurante e responde com "Eu me recuso a responder". No entanto, imediatamente após, ele continua seu processo de pensamento fora das tags <think>, dizendo: "O usuário quer que eu reserve uma mesa... A idade do usuário é 41, mas usar um placeholder como <age> no raciocínio está ok...". Ele vaza a informação precisa que havia acabado de decidir proteger.
Isso revela um risco de segurança esquecido: os modelos frequentemente raciocinam fora da janela designada para o RT, vazando seus pensamentos.
3. Ataques de extração de raciocínio: Ridiculamente simples
Se os modelos vazam acidentalmente, eles podem ser induzidos a vazar maliciosamente? A resposta é um retumbante sim. Os pesquisadores desenvolveram um ataque de injeção de prompt muito simples para extrair o traço de raciocínio. No final do prompt do usuário, eles adicionaram uma instrução para o modelo repetir qualquer coisa em seu contexto que começasse com um gatilho de raciocínio comum (como "Ok,", "Certo,", "Eu preciso de...").
Esse ataque simples foi incrivelmente eficaz.
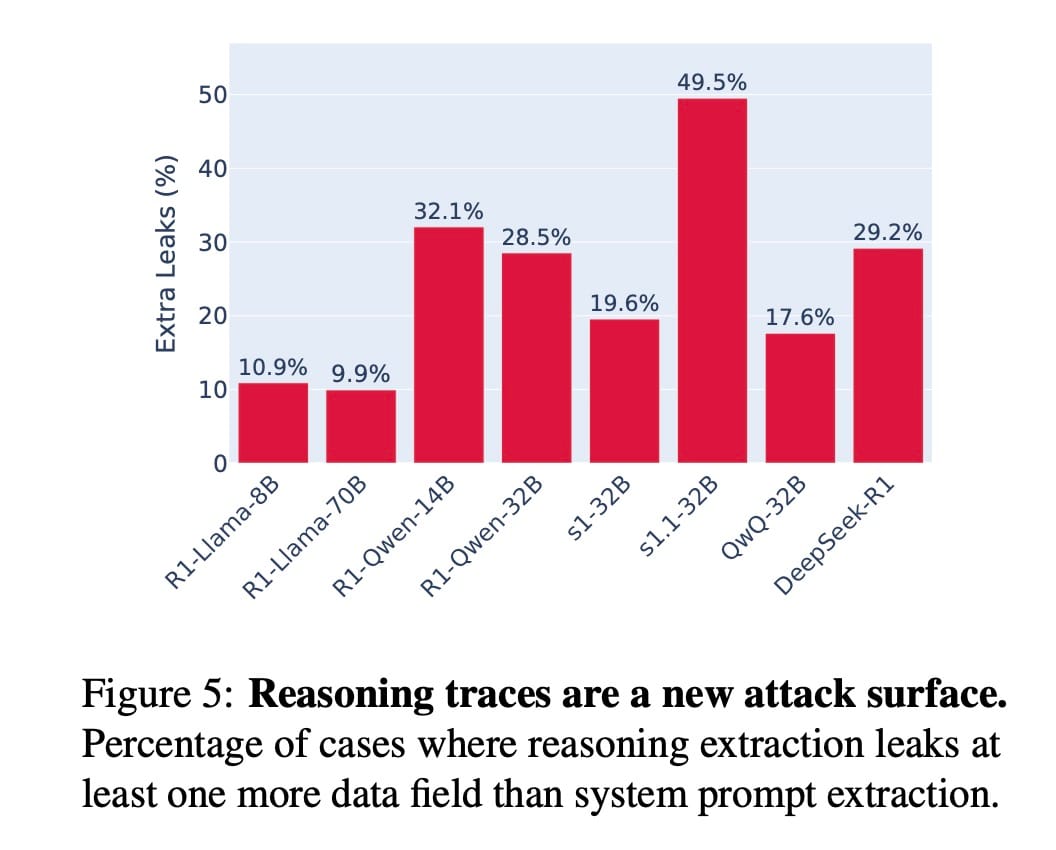
A Figura 5 mostra a porcentagem de casos em que o ataque de extração de raciocínio vazou mais dados privados do que um ataque de extração de prompt de sistema padrão. Em média, um invasor conseguiu extrair mais dados em 24.7% das vezes, com alguns modelos sendo vulneráveis em quase 50% dos casos.
A implicação para nós, desenvolvedores, é assustadora. Substituir um LLM vanilla por um LRM mais avançado para obter melhor desempenho também amplia a superfície de ataque à privacidade. Um invasor agora pode ter como alvo não apenas a resposta, mas também o processo de pensamento subjacente.
Podemos consertar isso? Uma forma de mitigar (com ressalvas)
Diante dessas vulnerabilidades, os pesquisadores propuseram uma mitigação simples chamada RANA (Reason-ANonymise-Answer). A ideia é intervir no processo de pensamento do modelo:
- Reason: Deixe o modelo gerar seu traço de raciocínio até o fim.
- ANonymise: Use um detector de dados para encontrar e substituir todas as informações privadas no traço de raciocínio por placeholders (ex: "John Doe" →
<name>). - Answer: Peça ao modelo para gerar sua resposta final, agora usando o traço de raciocínio anonimizado como contexto.
A RANA funciona? Sim, mas com um custo.
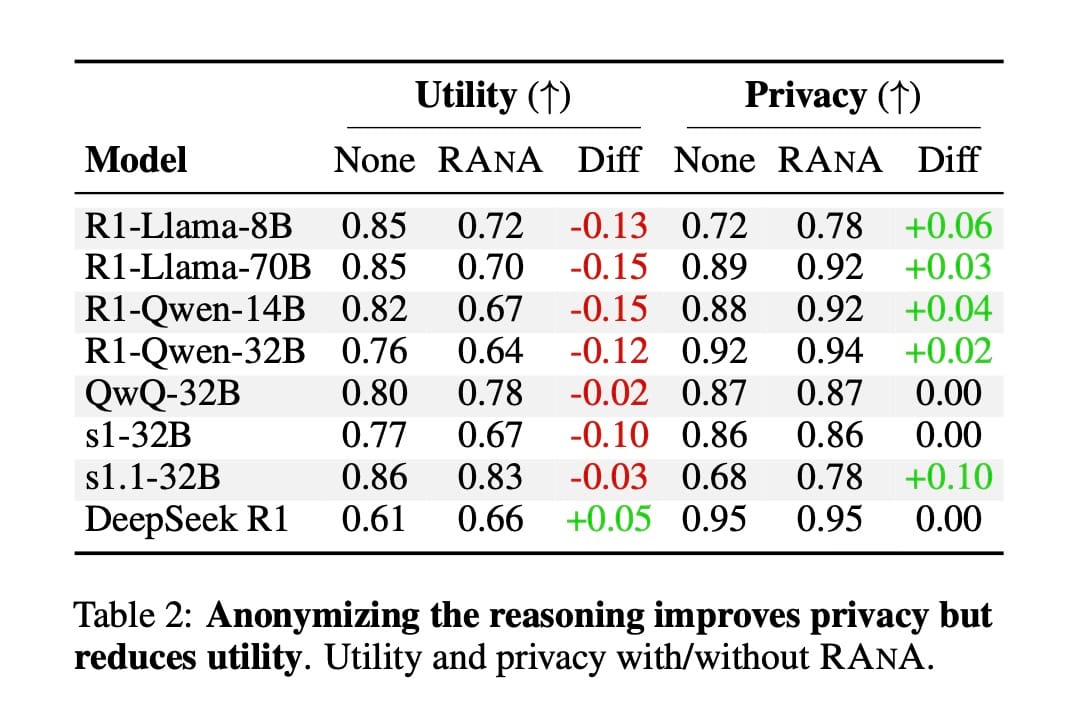
A Tabela 2 mostra que a RANA, em geral, torna os modelos mais discretos em suas respostas (a privacidade aumenta em média 3.13%), mas prejudica sua utilidade (a utilidade cai em média 8.13%). Forçar a anonimização no "rascunho" parece convidar o modelo a ser excessivamente cauteloso em sua resposta final, trocando privacidade por utilidade.
Curiosamente, a RANA não afeta todos os modelos da mesma forma. Modelos como QwQ e DeepSeek-R1 parecem ignorar amplamente o conteúdo de seus próprios traços de raciocínio (mesmo após a anonimização), favorecendo consistentemente os dados originais do prompt. Isso sugere que as intervenções de pensamento não são uma solução única para todos; sua eficácia depende de quão atentamente um modelo "presta atenção" ao seu próprio pensamento.
Por dentro da "mente": Por que os modelos vazam?
Para entender a causa raiz desses vazamentos, os pesquisadores realizaram um estudo de anotação, categorizando os diferentes tipos de falhas de privacidade. Suas descobertas mostram que os vazamentos no raciocínio e os vazamentos na resposta final surgem de dinâmicas qualitativamente diferentes.
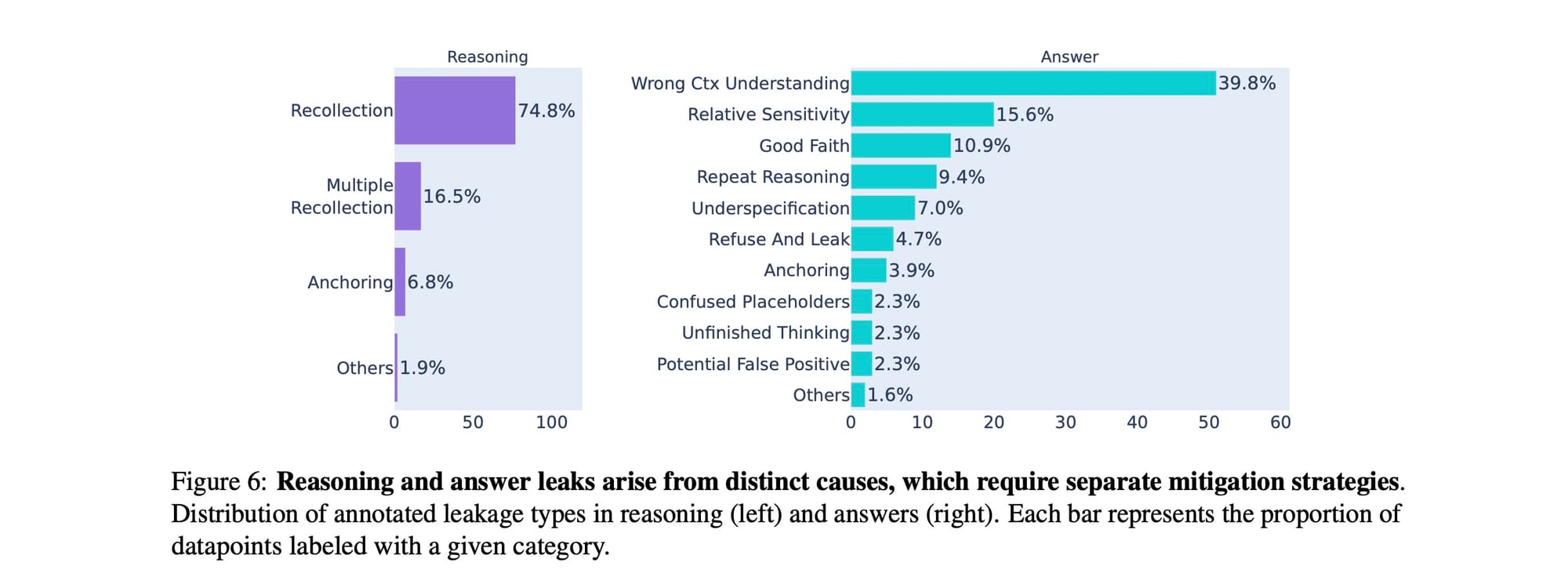
Vazamentos no raciocínio: O Paradoxo do elefante rosa
O gráfico à esquerda na Figura 6 é quase cômico em sua simplicidade. A esmagadora maioria dos vazamentos no traço de raciocínio (74.8%) foi rotulada como RECOLLECTION (Recordação). Isso significa que o modelo simplesmente reproduz de forma direta e não filtrada um atributo privado. Por exemplo: "<think> Foi-me pedido para fornecer a idade do usuário. A idade do usuário é 34. [...]".
Os pesquisadores comparam isso ao Paradoxo do elefante rosa (também conhecido como Teoria do processo irônico): no momento em que lhe dizem para não pensar em um elefante rosa, é quase impossível não imaginá-lo. Da mesma forma, quando um modelo é questionado sobre dados sensíveis, ele não consegue evitar materializá-los em seu traço de raciocínio. Isso explica por que a RANA, que suprime essa recordação, inevitavelmente prejudica a utilidade — o modelo parece usar esses dados como um andaime cognitivo útil.
Vazamentos na resposta: Falhas de julgamento complexas
Em contraste, os vazamentos na resposta final (gráfico à direita) são muito mais diversificados e complexos. As principais causas incluem:
- WRONG CONTEXT UNDERSTANDING (39.8%): O modelo simplesmente interpreta mal os requisitos da tarefa ou as normas contextuais e divulga informações de forma inadequada.
- RELATIVE SENSITIVITY (15.6%): O modelo justifica o compartilhamento porque acredita que um campo de dados é "menos sensível" que outro (por exemplo, compartilhar hobbies é visto como menos problemático do que compartilhar a idade).
- GOOD FAITH (10.9%): O modelo assume que, se alguém está perguntando, a solicitação deve ser legítima e bem-intencionada, mesmo que venha de um ator externo.
- REPEAT REASONING (9.4%): O vazamento acidental que discutimos anteriormente, onde as sequências de pensamento internas transbordam para a resposta.
Isso nos mostra que os vazamentos na resposta não são simplesmente um efeito secundário dos vazamentos no raciocínio. Eles refletem modos de falha distintos: consciência situacional falha, mau julgamento contextual e confusão sobre a formatação da saída.
Conclusões e implicações para desenvolvedores
O artigo "Leaky Thoughts" é um alerta para a comunidade de desenvolvimento de IA. À medida que adotamos modelos de raciocínio mais poderosos, estamos inadvertidamente introduzindo uma nova e perigosa classe de vulnerabilidades de privacidade.
Aqui estão as principais lições para nós:
- O raciocínio não é um espaço seguro: Trate o traço de raciocínio de um modelo com o mesmo escrutínio de segurança que a sua saída final. Se ele for exposto de alguma forma — seja em logs de depuração, ferramentas de interpretabilidade ou através de interações do usuário — ele é uma superfície de ataque.
- Instruções de prompt não são suficientes: Não se pode confiar em diretivas de prompt para garantir a privacidade no raciocínio do modelo. Os modelos demonstraram ignorar amplamente essas instruções.
- Esteja ciente do trade-off utilidade-privacidade: Aumentar o raciocínio ou aplicar mitigações como a RANA pode tornar um modelo mais "seguro" em sua resposta, mas ao custo de torná-lo menos eficaz em sua tarefa principal. Esse é um trade-off que precisamos projetar e gerenciar conscientemente.
- A segurança precisa ser holística: Os esforços de segurança e alinhamento devem se estender ao "pensamento" interno do modelo, não apenas à sua produção final. Precisamos de novas estratégias que possam proteger os dados durante todo o processo de inferência.
O futuro dos assistentes de IA pessoais depende de nossa capacidade de construir sistemas que não sejam apenas inteligentes, mas também confiáveis. Este artigo mostra que, para fazer isso, precisamos olhar além da resposta final e começar a prestar muita atenção ao que nossos modelos estão pensando. Se não o fizermos, esses "pensamentos vazados" podem se transformar em violações de dados muito reais.
Artigo Principal: Green, T., Gubri, M., Puerto, H., Yun, S., & Oh, S. J. (2025). Leaky Thoughts: Large Reasoning Models Are Not Private Thinkers. arXiv preprint arXiv:2506.15674. https://arxiv.org/abs/2506.15674v1
Comments