
IA na era da escassez de GPUs
AIVamos ficar dependentes de só consumir APIs de Inteligência Artificial ou vamos conseguir treinar IAs utilizando a CPU do nosso notebook? Pesquisadores viram uma maneira de realizar o refinamento de modelos com CPUs ao invés de GPUs. Eu explorei o artigo neste post.

Lembro-me vividamente de meados dos anos 2000, quando compilar o kernel do Linux no meu modesto desktop era um rito de passagem. A máquina esquentava, os ventiladores zumbiam em um crescendo frenético e, por horas, o computador se tornava um altar sagrado dedicado a uma única tarefa. Era um processo lento, quase meditativo. Naquela época, a Lei de Moore ainda ditava o ritmo da inovação, e a cada dois anos, podíamos esperar o dobro do poder de processamento pelo mesmo preço. Nós, desenvolvedores, surfávamos nessa onda de abundância computacional.
Hoje, o cenário é outro. A Lei de Moore fraqueja, e a nova fronteira da computação, a Inteligência Artificial, ergueu um muro alto e caro chamado GPU. Grandes Modelos de Linguagem (LLMs), as catedrais tecnológicas do nosso tempo, são construídos e, crucialmente, adaptados, sobre alicerces de hardware especializado que custam uma fortuna e consomem energia de uma pequena cidade. A inovação, que antes parecia um campo aberto, agora se assemelha a um clube exclusivo, com ingressos vendidos em dólares e silício. Para a maioria dos desenvolvedores, entusiastas e pequenas empresas, a barreira de entrada para o fine-tuning (o processo de especializar um LLM para uma tarefa específica) tornou-se proibitiva.
Nós, que vivemos e respiramos código, nos vemos em uma encruzilhada. Estamos fadados a ser meros consumidores de APIs oferecidas por um punhado de gigantes da tecnologia? A promessa de democratização da IA morreu na praia, afogada nos custos de hardware? É nesse cenário de aparente resignação que um trabalho recente, quase uma heresia em tempos de adoração à GPU, chamou minha atenção. Um artigo intitulado "LoRA Fine-Tuning Without GPUs: A CPU-Efficient Meta-Generation Framework for LLMS" propõe uma ideia tão simples quanto audaciosa: e se pudéssemos contornar a necessidade de GPUs para o fine-tuning, usando apenas a humilde CPU que todos temos em nossos laptops?
Como um velho desenvolvedor de software que já viu modas irem e virem, aprendi a ser cético. Mas também aprendi que as ideias mais disruptivas muitas vezes nascem da necessidade e da restrição. Este artigo não é apenas sobre uma nova técnica; é sobre resiliência, sobre encontrar um caminho alternativo quando a estrada principal está congestionada e pedagiada. É uma provocação que nos força a questionar o status quo e a repensar os dogmas que aceitamos sem pestanejar.
O dogma da GPU e a tirania do fine-tuning
Para entender a relevância desta proposta, precisamos primeiro dissecar o problema. Os LLMs, como o GPT da OpenAI ou o Llama da Meta, são modelos de fundação. Eles são como gênios da lâmpada com um conhecimento enciclopédico, mas sem um mestre específico. Para que eles se tornem úteis em tarefas do mundo real – como analisar o sentimento de reviews de clientes, gerar código em um dialeto específico de SQL ou atuar como um chatbot especializado em um determinado domínio, eles precisam ser "afinados" (fine-tuned).
O método tradicional, o full fine-tuning, envolve ajustar todos os bilhões de parâmetros do modelo. É como reeducar o gênio do zero. O custo computacional é astronômico, exigindo clusters de GPUs e semanas de treinamento. É um luxo para poucos.
Nos últimos anos, surgiram as técnicas de Parameter-Efficient Fine-Tuning (PEFT), que são uma espécie de atalho inteligente. Em vez de ajustar todos os parâmetros, elas modificam apenas uma pequena fração deles. A mais popular dessas técnicas é a Low-Rank Adaptation, ou LoRA. A ideia do LoRA é engenhosa: em vez de alterar diretamente uma matriz de pesos gigante (W_0) de uma camada do modelo, ele "congela" essa matriz e injeta um "adaptador" de baixo posto (DeltaW=BA), onde as matrizes B e A são muito menores que a original. No fine-tuning, apenas os parâmetros de A e B são treinados. Isso reduz drasticamente a necessidade de memória e computação, tornando o processo mais acessível.
Mas aqui está o "elefante na sala": mesmo o LoRA, o pináculo da eficiência, ainda exige GPUs para o treinamento. Para modelos massivos, o processo pode ser longo e pesado. A barreira foi reduzida, mas não eliminada. Continuamos dependentes do hardware caro e escasso. Isso cria uma casta de "sacerdotes da IA" com acesso aos templos de GPUs, enquanto a maioria de nós, a plebe, fica do lado de fora, esperando pelas migalhas de APIs pré-fabricadas.
A magia da CPU: combinando sabedorias existentes
É aqui que a proposta de Reza Arabpour e seus colegas entra como um sopro de ar fresco. A pergunta central que eles fazem é radical: podemos gerar novos adaptadores LoRA para novas tarefas sem usar GPUs? A resposta deles é um "sim" qualificado, e a abordagem é fascinante. Em vez de treinar um novo adaptador LoRA do zero usando descida de gradiente (o processo que exige a força bruta das GPUs), eles propõem construir um novo adaptador combinando, de forma inteligente, adaptadores pré-existentes.
Imagine que você tem um vasto banco de adaptadores LoRA já treinados para centenas de tarefas diferentes, um para resumir textos legais, outro para gerar poemas, um terceiro para responder perguntas sobre biologia, e assim por diante. Agora, você tem uma nova tarefa, por exemplo, classificar e-mails de suporte técnico. A intuição nos diz que essa nova tarefa pode ter semelhanças com outras já existentes. Talvez ela seja 30% parecida com a tarefa de "resumo de texto técnico" e 20% com a de "classificação de documentos".
A ideia do artigo é formalizar essa intuição. O método deles aprende um "meta-operador" que, para qualquer novo conjunto de dados, encontra os coeficientes ideais para misturar os adaptadores do banco e criar um novo, sob medida para a sua tarefa. E a beleza da coisa toda? Esse processo de combinação é leve o suficiente para rodar em uma CPU de laptop em questão de minutos.
Debaixo do capô: como a mágica acontece
O framework proposto, que eles chamam de "CPU-Efficient Meta-Generation Framework", pode ser decomposto em algumas etapas principais:
- Datasets como distribuições de probabilidade: O primeiro passo é tratar cada conjunto de dados (tanto os do banco quanto o novo) de uma maneira unificada. Eles representam cada dataset como uma distribuição de probabilidade. Isso permite que, independentemente do número de exemplos em cada um, eles possam ser comparados matematicamente.
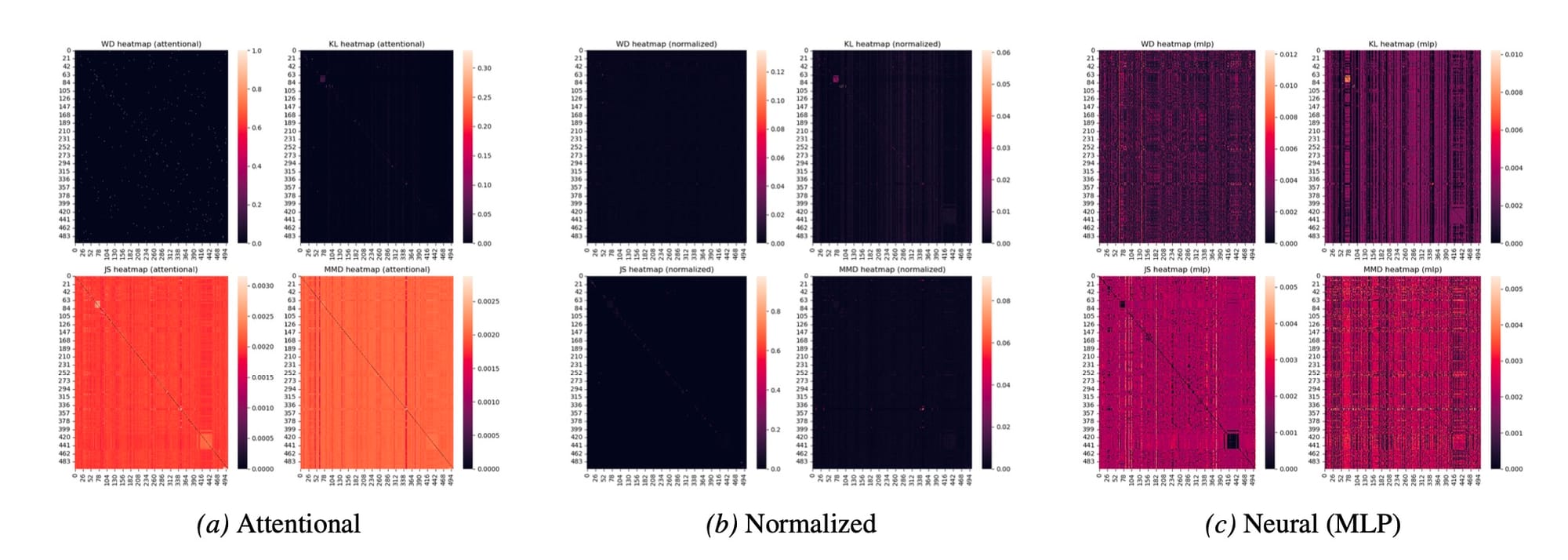
- Medindo a similaridade: Com os datasets representados como distribuições, o próximo passo é calcular a "distância" ou "dissimilaridade" entre o seu novo dataset e cada um dos datasets no banco. Para isso, eles experimentam com várias métricas consagradas, como a Distância de Wasserstein (WD), a divergência de Kullback-Leibler (KL), a divergência de Jensen-Shannon (JS) e a Maximum Mean Discrepancy (MMD). O resultado é um vetor de "pontuações de alinhamento" que quantifica o quão parecido o seu problema é de cada um dos problemas para os quais já existe uma solução (um adaptador LoRA).
- Gerando os pesos da mistura: Agora vem o pulo do gato. Essas pontuações de alinhamento são usadas para gerar um conjunto de pesos que determinará a proporção de cada adaptador pré-treinado na mistura final. Os autores testaram três abordagens para essa etapa:
- Abordagem atencional (Attentional approach): Esta é a versão mais simples e direta. As pontuações de distância são passadas por uma função
softmin. A lógica é que, quanto menor a distância (maior a similaridade), maior deve ser o peso do adaptador correspondente. Os autores fazem uma analogia inteligente com os mecanismos de atenção dos Transformers, onde os datasets do banco agem como "chaves" (keys) e os adaptadores pré-treinados como "valores" (values). - Abordagem normalizada (Normalized approach): Uma variação da abordagem atencional, onde os vetores de distância são primeiro normalizados (padronizados para ter média zero e variância um) antes de aplicar o
softmin. Essa pequena mudança, como veremos, tem um impacto surpreendente nos resultados. - Abordagem neural (Neural approach): Esta é a versão mais sofisticada, onde uma pequena rede neural (um Multi-Layer Perceptron, ou MLP) é inserida entre as pontuações de alinhamento e a geração dos pesos. A ideia é que a MLP possa aprender relações não-lineares mais complexas entre as similaridades dos datasets e a mistura ótima de adaptadores para maximizar a performance na tarefa final. E o detalhe crucial: essa MLP é pequena o suficiente para ser treinada também em uma CPU.
- Abordagem atencional (Attentional approach): Esta é a versão mais simples e direta. As pontuações de distância são passadas por uma função
- A Grande mistura: Uma vez que os pesos (coeficientes) são determinados, o novo adaptador LoRA é simplesmente uma soma ponderada dos adaptadores do banco. Ou seja, o adaptador final é uma combinação linear dos parâmetros dos adaptadores existentes, um "coquetel" de especialidades.
O resultado é um conjunto de parâmetros LoRA gerado "do nada" (zero-shot), sem um único ciclo de GPU para treinamento com descida de gradiente. É uma forma de transferir conhecimento de múltiplas fontes para uma nova tarefa de maneira extremamente eficiente.
A Hora da verdade: os resultados experimentais
Tudo isso parece muito elegante na teoria, mas no mundo do software, a prova do pudim está em comê-lo. E os resultados apresentados no artigo são, no mínimo, intrigantes.
Os pesquisadores usaram o modelo Mistral-7B-Instruct-v0.2 como base e um banco de dados com 502 pares de dataset-adaptador do repositório "Lots-of-LoRAs". Eles compararam o desempenho dos adaptadores gerados por CPU com dois baselines cruciais:
- O modelo base: O Mistral-7B sem nenhum fine-tuning, que representa o que um usuário com recursos limitados faria. Ele obteve uma pontuação Rouge-L (uma métrica que mede a sobreposição de texto) de 0.192.
- O oráculo da GPU: O desempenho de um adaptador LoRA treinado tradicionalmente com GPUs para a mesma tarefa, que representa o "teto" de desempenho. Ele alcançou uma pontuação de 0.746.
O objetivo dos adaptadores gerados por CPU é, portanto, se posicionar em algum lugar entre esses dois extremos. E eles conseguem. A melhor configuração (a abordagem normalizada com a divergência JS) alcançou uma pontuação Rouge-L de 0.520.
Vamos parar para pensar nesse número. O método proposto, rodando apenas em CPU, conseguiu reduzir a lacuna de desempenho entre o modelo base e o modelo totalmente afinado em GPU em mais da metade. Isso é um salto de 0.328 pontos de performance, obtido sem a necessidade de hardware especializado. Todas as abordagens, mesmo a mais simples "Atencional", superaram significativamente o modelo base.
Mas o resultado mais provocador, na minha opinião, é outro. Surpreendentemente, a abordagem Neural, a mais complexa e teoricamente mais poderosa (com garantias de otimalidade), não apresentou um desempenho significativamente melhor que suas contrapartes mais simples, a Atencional e a Normalizada. Em alguns casos, chegou a ser pior. Isso é uma bela lição de humildade para nós, engenheiros, que muitas vezes nos apaixonamos pela complexidade. Às vezes, uma solução mais simples e direta não é apenas "boa o suficiente", ela é simplesmente melhor.
A análise da distribuição dos coeficientes (Figura 1 do artigo) oferece uma pista do porquê. A abordagem Normalizada gera matrizes de coeficientes extremamente esparsas. Isso significa que, para cada nova tarefa, ela identifica e se concentra em apenas um ou dois adaptadores pré-existentes muito relevantes, ignorando o resto. As abordagens Atencional e Neural, por outro lado, tendem a criar uma "sopa" mais distribuída de coeficientes, misturando um pouco de tudo. Na prática, parece que a especialização (encontrar os poucos "especialistas" certos) supera a generalização (misturar a sabedoria de muitos).
Entre a promessa e a prática
Como todo bom cético, meu trabalho não é apenas aplaudir, mas também questionar. A abordagem do artigo é, sem dúvida, brilhante em sua simplicidade e eficácia. No entanto, existem "elefantes na sala" que precisam ser apontados.
O primeiro, e mais óbvio, é a dependência de um grande e diverso banco de adaptadores pré-treinados. O método não cria conhecimento novo; ele o recombina. Sua eficácia está diretamente ligada à qualidade e à abrangência da "biblioteca" de LoRAs disponíveis. Isso cria um problema de "ovo e galinha": para que a geração por CPU seja útil, alguém, em algum lugar, ainda precisa fazer o trabalho pesado de treinar centenas de adaptadores em GPUs. O método democratiza o uso e a adaptação, mas não a criação fundamental dos blocos de construção.
O segundo ponto é a comparação com outras técnicas de PEFT. O artigo se concentra em superar a barreira da GPU, mas o mundo do PEFT é vasto. Técnicas como QLoRA (que combina LoRA com quantização agressiva) já reduziram drasticamente os requisitos de memória de GPU, permitindo o fine-tuning em GPUs de consumidor. Outras abordagens, como VeRA, tentam reduzir ainda mais o número de parâmetros treináveis, aprendendo apenas vetores de escalonamento para matrizes aleatórias congeladas. Onde o método de meta-geração por CPU se encaixa nesse espectro? Ele não compete diretamente com essas técnicas em termos de performance final (os próprios autores admitem que não alcançam o desempenho do fine-tuning em GPU), mas sim em acessibilidade. É um trade-off: performance máxima versus custo zero (de hardware especializado). Para muitos projetos, "bom o suficiente" e imediato é muito melhor do que "perfeito" e inacessível.
Além disso, a aplicabilidade prática depende da existência de um "hub" centralizado e bem-curado de adaptadores LoRA, como o "Lots-of-LoRAs" usado no estudo. A padronização de arquiteturas de modelos e formatos de adaptadores será crucial para que um ecossistema assim floresça.
Por fim, a própria natureza do método – combinar especialistas existentes – pode limitar sua capacidade de inovar em domínios verdadeiramente novos, para os quais não existem análogos próximos no banco de dados. Ele é excelente para interpolação (encontrar soluções para problemas que ficam "entre" problemas conhecidos), mas pode ter dificuldades com a extrapolação radical.
O futuro é híbrido e a provocação continua
Apesar das críticas, o valor deste trabalho é inegável. Ele nos força a sair da inércia e a pensar em soluções híbridas. Talvez o futuro não seja uma batalha de "CPU vs. GPU", mas uma colaboração inteligente. Uma das sugestões mais interessantes dos autores é usar este método de CPU não como um fim em si mesmo, mas como uma forma de inicialização de adaptadores LoRA. Imagine o cenário: você gera um adaptador "bom o suficiente" em sua CPU em poucos minutos. Em seguida, se você tiver acesso, mesmo que limitado, a uma GPU, você pode usar esse adaptador pré-aquecido como ponto de partida para um fine-tuning muito mais rápido e barato. É o melhor dos dois mundos.
Este artigo é um lembrete poderoso de que a inovação não é apenas sobre construir modelos maiores e mais potentes. É também sobre engenhosidade, eficiência e, acima de tudo, acessibilidade. Ele nos mostra que as restrições, longe de serem um obstáculo, podem ser o principal catalisador para a criatividade. Em uma indústria obcecada com escala e força bruta, uma abordagem que valoriza a elegância é mais do que bem-vinda; é necessária.
Para mim, o "feiticeiro da CPU" que emerge deste artigo não faz mágica. Ele pratica a magia, transformando recursos comuns (CPU e dados existentes) em algo de grande valor (inteligência artificial especializada). Ele nos lembra dos tempos de compilar o kernel, quando a paciência e a inteligência eram mais importantes do que o poder de fogo do hardware.
A grande questão que fica, e que eu deixo para reflexão, é: estamos construindo uma indústria de IA que se parece com a indústria farmacêutica, com P&D concentrado em poucos laboratórios gigantescos, ou estamos construindo algo que se parece com o ecossistema de código aberto, onde a inovação pode vir de qualquer garagem com um laptop e uma boa ideia?
Trabalhos como este me dão a esperança de que a segunda opção ainda está ao nosso alcance. A estrada é longa, mas a provocação foi lançada. E na nossa área, uma boa provocação é, muitas vezes, o primeiro passo para a próxima grande revolução.
Fontes e Leitura Adicional:
- Fonte Principal: LORA Fine-Tuning Without GPUs: A CPU-Efficient Meta-Generation Framework for LLMS https://arxiv.org/abs/2507.01806v1
- Mistral 7B: https://arxiv.org/abs/2310.06825
- QLoRA: QLoRA: Efficient Finetuning of Quantized LLMs https://arxiv.org/abs/2305.14314
- LoRA: LoRA: Low-Rank Adaptation of Large Language Models. https://arxiv.org/abs/2106.09685
- Hugging Face - PEFT: https://huggingface.co/docs/peft/index
Comments