
Diagnóstico e análise de documentos médicos com IA
Bio-MedicinaDescubra como LLMs como LLaMA-v3 podem revolucionar o diagnóstico médico com privacidade e explicabilidade, através de uma arquitetura inovadora ajustada com LoRA e implementada localmente.

A medicina moderna está cada vez mais dependente da análise de grandes volumes de dados. Relatórios clínicos, prontuários de pacientes e resultados de exames contêm informações vitais que, quando processadas eficientemente, podem transformar o diagnóstico e o tratamento. No entanto, a vastidão e a natureza não estruturada desses dados representam um desafio significativo. É aqui que os Grandes Modelos de Linguagem (LLMs) entram em cena, prometendo revolucionar a forma como interagimos com as informações médicas.
O desafio da confiança e privacidade em IA médica
Apesar do potencial incrível dos LLMs em diversas áreas, sua aplicação em saúde levanta uma preocupação fundamental: privacidade e confiança. Modelos de LLM baseados em nuvem, como os oferecidos por grandes empresas, muitas vezes processam dados em servidores externos, o que gera apreensão sobre a segurança de informações sensíveis de pacientes. Violar a privacidade de dados médicos não só tem sérias implicações éticas, mas também pode levar a consequências legais severas. A falta de transparência sobre como esses dados são usados e armazenados é uma barreira significativa para a adoção generalizada de LLMs em ambientes clínicos. Muitos desses serviços podem reter e revisar as entradas do usuário, e as conversas podem ser acessadas por funcionários da empresa, levantando bandeiras vermelhas para dados confidenciais.
Outro ponto é a dependência de serviços online. Se um LLM crucial para o diagnóstico estiver hospedado na nuvem e o serviço cair, operações críticas podem ser interrompidas. Além disso, a capacidade de personalização e controle sobre o modelo é frequentemente limitada, dependendo das configurações do provedor. Isso pode impedir que hospitais e clínicas adaptem a IA às suas necessidades específicas ou garantam que ela esteja em conformidade com regulamentações locais de privacidade de dados.
Modelos mais antigos e menores, como BioBERT e BioGPT, foram marcos importantes no processamento de linguagem natural biomédica. BioBERT, com 110 milhões de parâmetros, e BioGPT, com 1.5 bilhão, demonstraram excelentes resultados em tarefas como reconhecimento de entidade nomeada e resposta a perguntas em textos biomédicos. No entanto, comparados aos LLMs modernos como LLaMA e PaLM, que podem ter centenas de bilhões de parâmetros, eles são relativamente pequenos, limitando sua capacidade de lidar com a complexidade inerente a tarefas médicas avançadas.
Uma nova abordagem: LLMs locais e confiáveis para diagnóstico
Para enfrentar esses desafios, o artigo "LLM-Driven Medical Document Analysis: Enhancing Trustworthy Pathology and Differential Diagnosis" propõe uma plataforma robusta de análise de documentos médicos que prioriza a privacidade e a confiança. A chave para essa solução é o ajuste fino (fine-tuning) de um modelo LLaMA-v3 usando a técnica de adaptação de baixo posto (Low-Rank Adaptation - LoRA). A ideia é simples e poderosa: em vez de depender de serviços de LLMs online, o sistema é projetado para ser implementado localmente, dentro da infraestrutura de um hospital ou clínica. Isso garante que os dados sensíveis dos pacientes nunca saiam do ambiente controlado da instituição.
Este modelo ajustado é otimizado especificamente para tarefas de diagnóstico diferencial e previsão de patologias. Ele utiliza o DDXPlus, um dos maiores conjuntos de dados de referência para diagnóstico diferencial, o que permite ao modelo demonstrar desempenho superior em ambas as tarefas.
O motor por trás do diagnóstico
A arquitetura proposta é um dos pontos altos deste trabalho acadêmico. Ela é construída sobre o modelo LLaMA-v3 da Meta, que foi escolhido por seu desempenho robusto, escalabilidade e capacidade de adaptação. A versão específica utilizada é a "Meta-Llama-3.1-8B-Instruct", destacando a escolha por um modelo de ponta que pode ser otimizado para o domínio médico.
Vamos dar uma olhada na figura 1, que ilustra essa arquitetura:
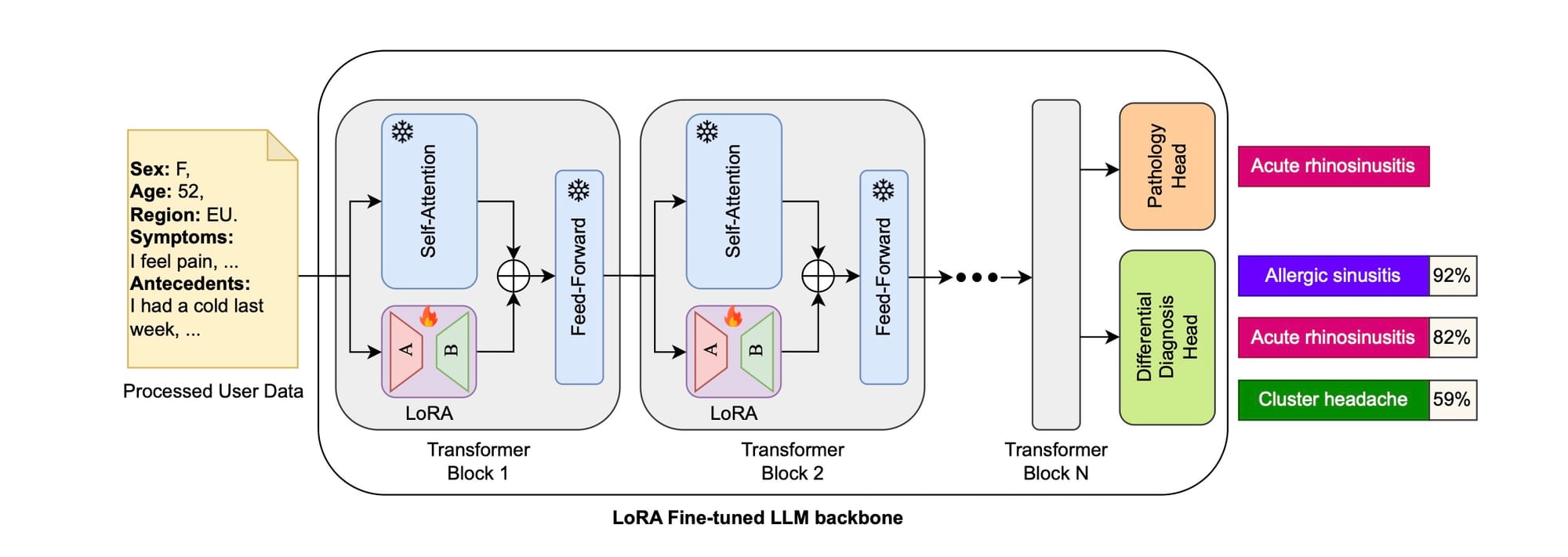
No coração do sistema está o "LLM Backbone Ajustado com LoRA". Esse backbone processa os dados do usuário, que incluem informações demográficas (sexo, idade, região) e sintomas. A técnica LoRA é aplicada especificamente aos módulos de autoatenção dentro de cada bloco Transformer do LLaMA-v3, enquanto os módulos MLP (Multi-Layer Perceptron) permanecem inalterados. Isso permite uma adaptação eficiente do modelo para tarefas específicas do domínio, como previsão de patologias e diagnóstico diferencial.
Após o processamento pelos blocos Transformer ajustados com LoRA, a saída é alimentada em duas "cabeças" lineares adicionais: uma "Pathology Head" para previsão da patologia principal (por exemplo, "rinossinusite aguda") e uma "Differential Diagnosis Head" para gerar uma lista de diagnósticos diferenciais prováveis com suas respectivas probabilidades (por exemplo, "sinusite alérgica 92%", "rinossinusite aguda 82%", "cefaleia em salvas 59%"). Esse design modular permite que o sistema forneça tanto um diagnóstico primário quanto uma visão mais abrangente das possíveis condições, o que é crucial em um cenário clínico real onde muitas patologias podem ter sintomas sobrepostos.
Não sabe o que são Transformers? Eu explico neste texto aqui.
A experiência do usuário: uma plataforma prática
A usabilidade é um fator chave para a adoção de qualquer ferramenta médica. Pensando nisso, os pesquisadores desenvolveram uma interface web intuitiva para a plataforma de pré-diagnóstico. Essa interface permite que os usuários submetam seus documentos médicos não estruturados e recebam resultados diagnósticos precisos e explicáveis.
A figura 2 detalha o pipeline da plataforma:
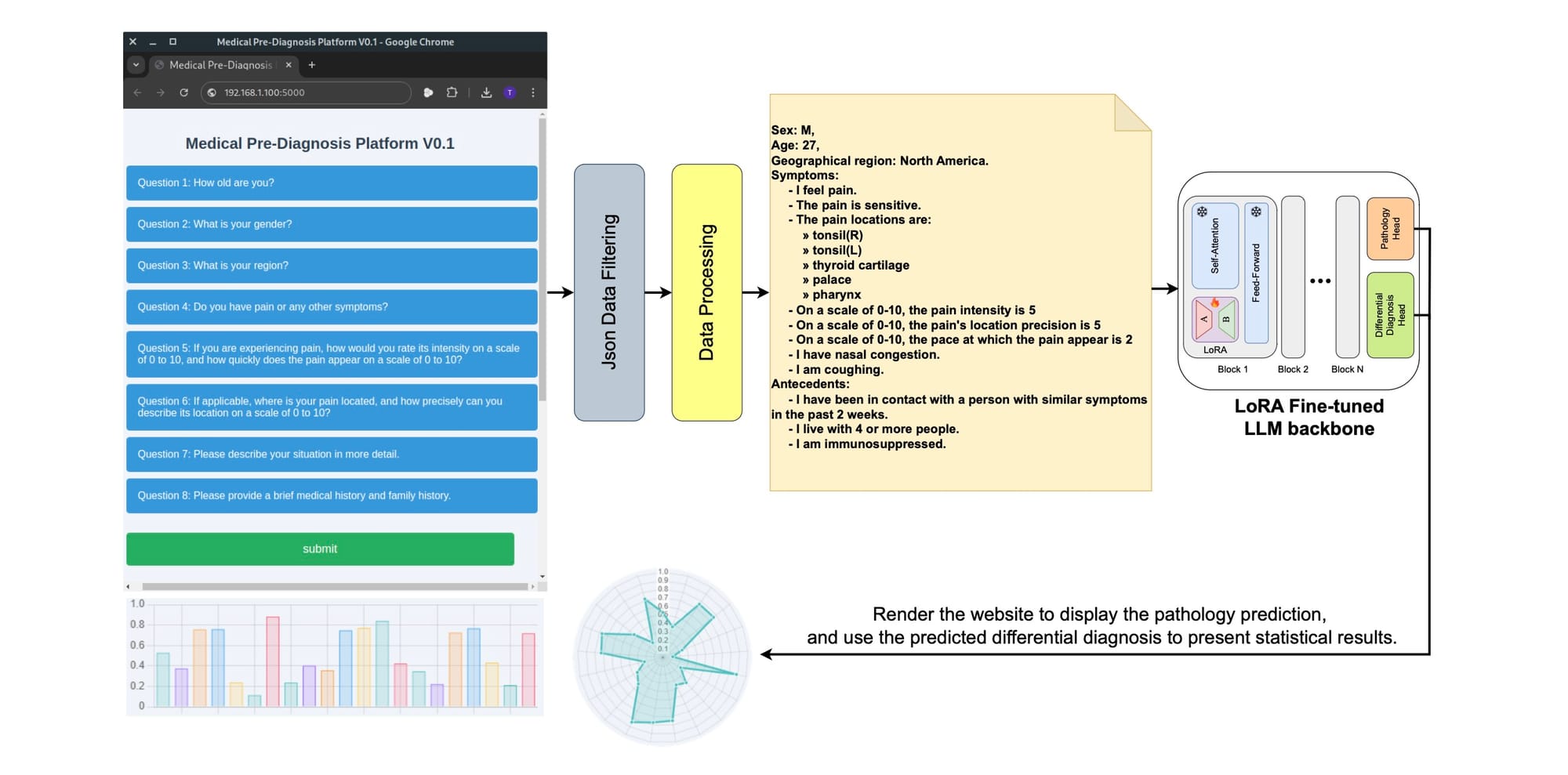
O processo começa com o usuário interagindo com o front-end, que é construído com JavaScript e Chart.js. O usuário insere dados como idade, sexo, sintomas e histórico médico em um formulário. Esses dados são então submetidos ao back-end, que utiliza Flask. O back-end é responsável por gerenciar as interações do usuário, validar e processar os dados de entrada usando expressões regulares, e então passá-los para o modelo de LLM ajustado.
A inferência do modelo acontece em um servidor com GPU, e o Flask orquestra esse processo. Uma vez que o LLM analisa os dados e faz as previsões, o back-end prepara os resultados e os envia de volta ao front-end. O JavaScript então processa esses resultados e usa Chart.js para criar gráficos dinâmicos (como gráficos de barras e de radar) que visualizam as previsões de patologia e os diagnósticos diferenciais de forma clara e interativa, aprimorando a interpretabilidade.
A figura 3 mostra a interface do usuário em ação:
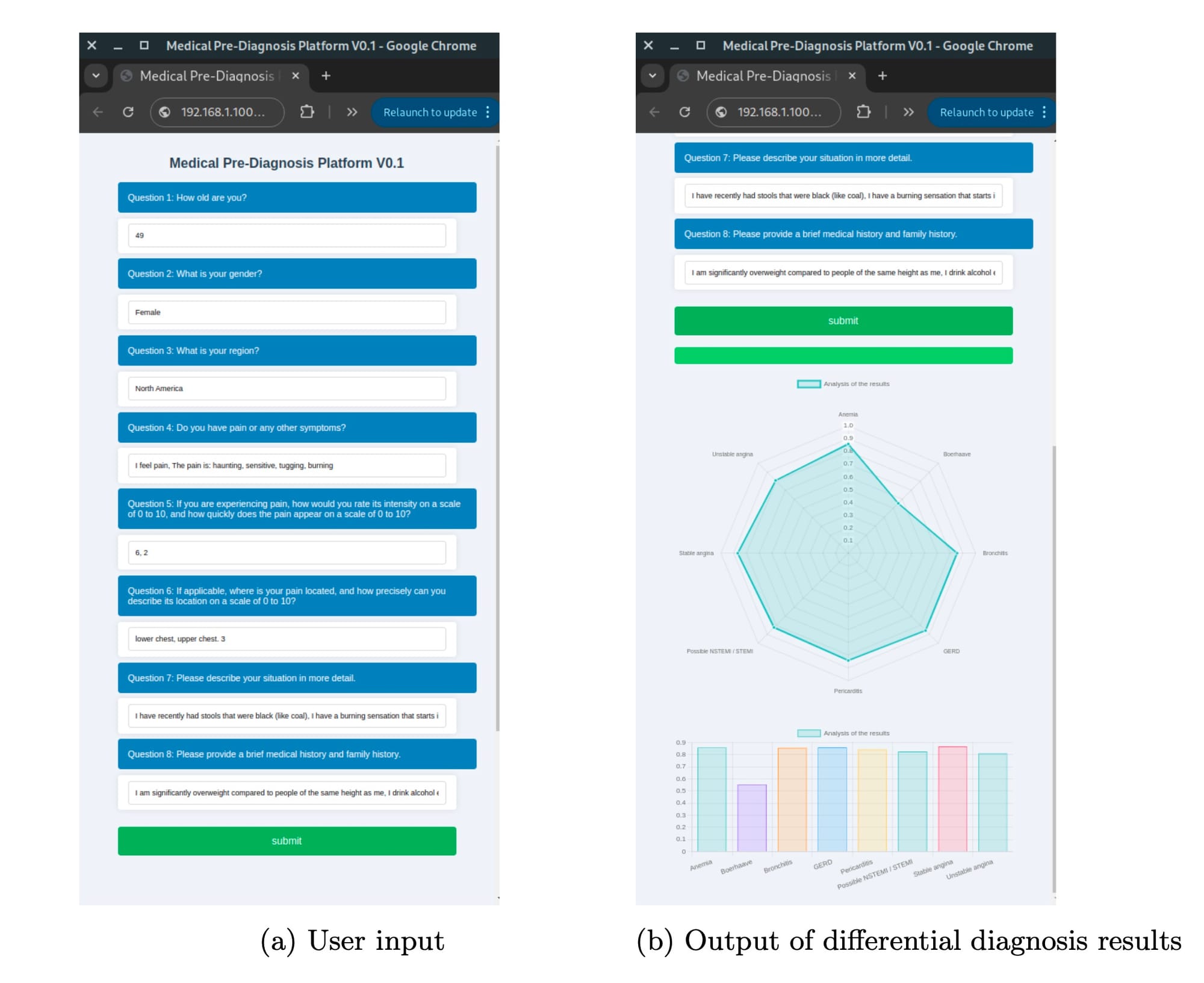
A Figura 3 (a) exibe a interface de entrada do usuário, onde 8 perguntas médicas básicas (como idade, sexo, região, sintomas e histórico médico) são apresentadas. Após o envio, uma barra de progresso indica que o LLM está realizando a inferência. A Figura 3 (b) mostra a saída dos resultados do diagnóstico diferencial, apresentados em gráficos de radar e de barras. Essa abordagem centrada no usuário, com visualizações claras, torna o sistema acessível até mesmo para não especialistas, ajudando a aliviar o congestionamento em instalações de saúde ao fornecer um pré-diagnóstico inicial.
Por trás dos panos: Ajuste fino com LoRA
Programadores e engenheiros de software sabem que treinar ou ajustar modelos grandes pode ser um pesadelo computacional. É aí que o LoRA brilha. Em vez de ajustar todos os bilhões de parâmetros de um LLM, o LoRA introduz uma pequena quantidade de matrizes de baixo posto em cada camada da arquitetura do Transformer. Isso significa que apenas uma pequena fração dos parâmetros originais precisa ser treinada, enquanto a maioria dos pesos do modelo pré-treinado permanece "congelada".
Pense assim: se o modelo original é uma orquestra gigantesca, ajustar o modelo completo seria ensinar cada músico a tocar um novo instrumento ao mesmo tempo. Com LoRA, é como se você adicionasse apenas alguns novos músicos (as matrizes de baixo posto) que são especialistas na nova música, enquanto o resto da orquestra (os pesos congelados) continua tocando a melodia original. Isso reduz drasticamente o uso de memória e os requisitos computacionais, tornando o ajuste fino muito mais eficiente e viável em ambientes com recursos limitados.
Para o LLaMA-v3, os autores aplicaram LoRA especificamente nos módulos de autoatenção de cada bloco Transformer. Isso permite que o modelo se adapte a padrões linguísticos e contextos médicos sem a necessidade de um re-treinamento completo, que seria proibitivamente caro.
Os dados que o impulsionam: DDXPlus
A qualidade de qualquer modelo de IA depende da qualidade dos dados com os quais ele é treinado. Para esta pesquisa, os autores utilizaram o DDXPlus, um dos maiores conjuntos de dados publicamente disponíveis para diagnóstico diferencial. O DDXPlus contém cerca de 1.3 milhão de registros sintéticos de pacientes, cada um com sintomas, histórico médico e as condições reais (ground truth). Cobrindo 49 patologias e diversas faixas etárias, gêneros e históricos médicos, ele fornece um terreno fértil para treinar modelos robustos de diagnóstico.
É importante notar que, como a patologia real de um paciente nem sempre é classificada em primeiro lugar no diagnóstico diferencial do DDXPlus, os autores não usaram as probabilidades de cada patologia para treinamento, mas sim a lista de diagnósticos diferenciais de comprimento variável. Eles se concentraram em duas tarefas principais: previsão de patologia (identificar a única patologia correta) e diagnóstico diferencial (prever uma lista de possíveis patologias).
Colocando à prova: Métricas de desempenho e resultados
A avaliação de um modelo médico não é trivial; exige métricas rigorosas. Os autores usaram Accuracy, Precision, Recall, F1-score e Ground Truth Pathology Accuracy (GTPA).
- Accuracy: A proporção geral de previsões corretas.
- Precision: A proporção de previsões positivas corretas entre todas as previsões positivas. Essencial para evitar falsos positivos em medicina.
- Recall: A proporção de previsões positivas corretas entre todas as instâncias positivas reais. Fundamental para garantir que o modelo não perca casos reais.
- F1-score: Uma média harmônica de Precision e Recall, fornecendo um equilíbrio entre as duas.
- GTPA: Avalia se o diagnóstico diferencial previsto pelo modelo inclui a patologia real do paciente.
Previsão de Patologia:
Para a tarefa de previsão de patologia, o modelo proposto alcançou resultados impressionantes. Com uma Accuracy de 99.81%, Precision de 96.54%, Recall de 94.34% e F1-score de 94.81%. Embora a Accuracy seja ligeiramente inferior à do método DDxT (99.98%), o desempenho do modelo ainda é considerado adequado para aplicações práticas devido à sua alta precisão.
Diagnóstico Diferencial:
Nesta tarefa, o modelo proposto superou significativamente os métodos de linha de base. Alcançou o GTPA mais alto (99.94%), superando BASD (99.30%) e AARLC (99.92%), indicando uma concordância mais consistente com a patologia real. Em termos de Precision, o modelo atingiu 98.18%, superando BASD (88.34%), AARLC (69.53%) e DDxT (94.84%). Isso sugere que o método proposto é mais eficaz em evitar diagnósticos falsos positivos, resultando em previsões mais confiáveis. O Recall foi de 97.91%, comparável a AARLC (97.73%) e ligeiramente superior a DDxT (94.65%). Por fim, o F1-score de 98.01% indica um equilíbrio ótimo entre Precision e Recall, superando o estado da arte por uma margem considerável.
Entendendo o "porquê": Recursos de explicabilidade
Um dos pilares da confiança em sistemas de IA, especialmente na medicina, é a explicabilidade. Não basta que o modelo acerte; precisamos entender como ele chegou àquela conclusão. O artigo aborda isso visualizando os padrões de autoatenção nas camadas rasa, intermediária e profunda do modelo LLaMA-v3 ajustado com LoRA.
Em termos simples, os mapas de autoatenção mostram quais partes do texto de entrada o modelo está "prestando atenção" ao fazer uma previsão.
- Camada rasa (shallow layer): O modelo geralmente atende amplamente a todos os tokens de entrada, o que é útil para extração de características abrangente.
- Camada intermediária (middle layer): A autoatenção seletivamente foca em elementos específicos, como palavras-chave que indicam locais de dor ou intensidade, mostrando que o modelo está destilando informações relevantes.
- Camada profunda (deep layer): A atenção se concentra predominantemente nos tokens iniciais, alinhando-se com o objetivo de classificação de sequência, onde as informações são consolidadas em um token especial de início de texto.
Essa consistência nos padrões de autoatenção ajuda a distinguir entre previsões corretas e incorretas, aumentando a interpretabilidade e a confiabilidade do modelo.
Analisando casos de falha
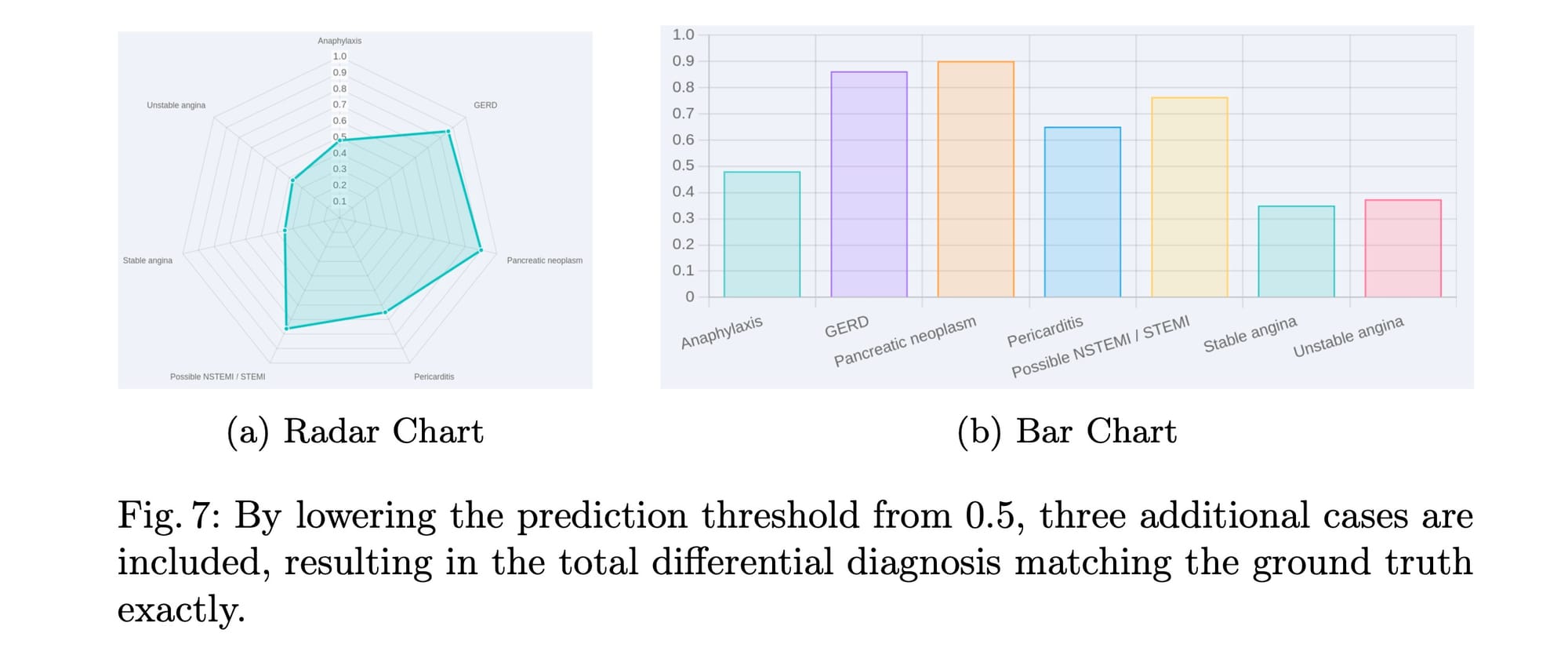
Mesmo com uma precisão superior a 99%, é crucial analisar os casos de falha em aplicações médicas devido à sua natureza crítica. Os autores investigaram um cenário onde o diagnóstico diferencial previsto continha apenas 4 casos, enquanto a verdade fundamental (ground truth) incluía 7. A figura 6 do artigo ilustra essa falha de previsão.
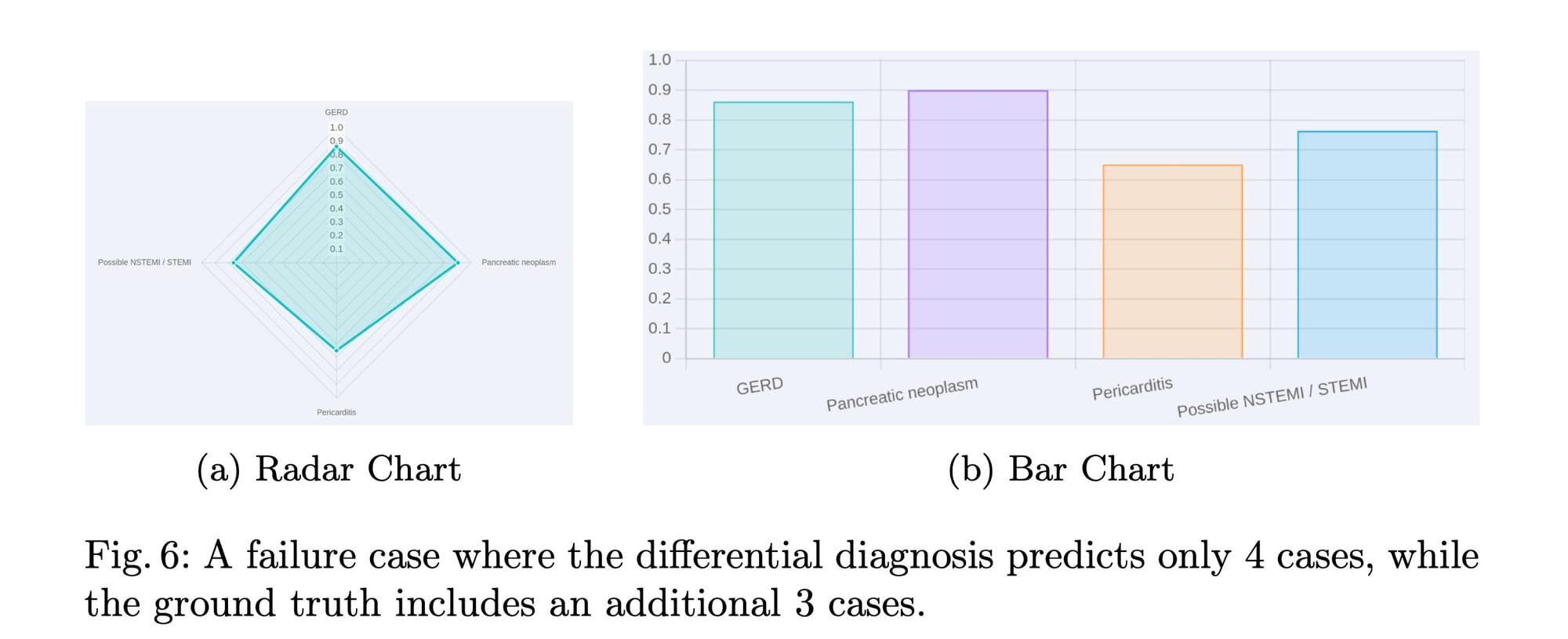
A análise revelou que essa discrepância não se devia a uma incapacidade intrínseca do modelo, mas sim ao limiar de probabilidade usado para identificar as categorias de patologia de alta probabilidade. Ao aplicar uma função sigmoide à cabeça de diagnóstico diferencial e usar um limiar de 0.5, apenas 4 casos foram previstos.
A solução foi surpreendentemente simples: reduzir o limiar de previsão de 0.5 para 0.35. Com essa pequena mudança, três casos adicionais foram incluídos, fazendo com que o diagnóstico diferencial correspondesse exatamente à verdade fundamental (figura 7 no artigo). Isso indica que o modelo é capaz de identificar as patologias corretas, mas o ajuste do limiar é crucial para capturar todos os resultados potenciais, especialmente porque o DDXPlus não usa probabilidades explícitas para treinamento.
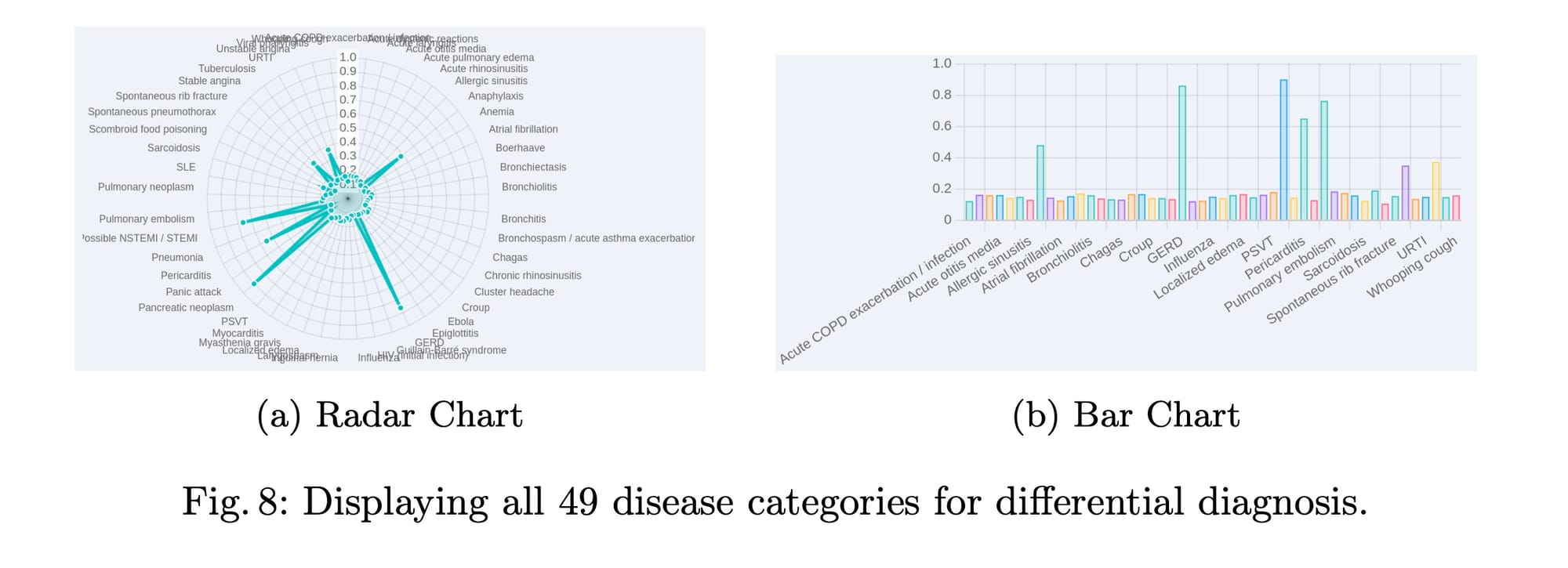
A capacidade do modelo de aprender intrinsecamente estimativas de probabilidade com base nos sintomas do paciente e informações básicas, mesmo sem supervisão probabilística explícita, é notável. Além disso, ao reduzir o limiar para 0, o modelo pode exibir todas as 49 categorias de doenças, revelando que as 7 categorias que se alinham com o diagnóstico diferencial real têm probabilidades significativamente mais altas do que as outras 42 (figura 8 no artigo). Essa análise de falhas reforça a robustez do modelo e a importância de ajustar os hiperparâmetros de inferência para obter os melhores resultados em cenários práticos.
Perspectiva crítica: Comparando com outras tecnologias
Para programadores e engenheiros de software, é essencial entender onde esta solução se encaixa no panorama da IA médica e como ela se compara a outras abordagens.
Med-PaLM 2 e GPT-4:
Modelos como Med-PaLM 2 da Google e GPT-4 da OpenAI representam o estado da arte em LLMs de propósito geral e específicos para o domínio médico. Med-PaLM 2, por exemplo, atingiu altos níveis de precisão em exames médicos e demonstrou melhorias substanciais nas respostas a perguntas médicas do consumidor. No entanto, sua acessibilidade é limitada a um número restrito de clientes Google Cloud, e ele não possui uma interface web aberta ao público. Mais importante, a dependência de serviços em nuvem para dados sensíveis de saúde ainda levanta sérias preocupações de privacidade. Usuários e reguladores se preocupam com a retenção de dados e o controle sobre informações protegidas.
A solução proposta no artigo se diferencia por seu foco explícito na implementação local. Isso elimina a necessidade de transmitir dados sensíveis do paciente para servidores externos, proporcionando controle total sobre a informação e garantindo conformidade com regulamentações como a HIPAA (nos EUA), GDPR (na Europa) ou LGPD (no Brasil). Enquanto modelos como Med-PaLM 2 são poderosos, a natureza "caixa-preta" e o modelo de implantação em nuvem de muitos LLMs proprietários podem ser um obstáculo significativo em ambientes de saúde, onde a transparência e o controle de dados são primordiais.
BioBERT e BioGPT:
Como mencionado anteriormente, BioBERT e BioGPT foram desenvolvidos especificamente para texto biomédico. Eles adaptaram arquiteturas como BERT e GPT-2 para o domínio médico, mostrando melhorias em tarefas como reconhecimento de entidades e resposta a perguntas. A principal diferença aqui é a escala. BioBERT (110 milhões de parâmetros) e BioGPT (1.5 bilhão de parâmetros) são ordens de magnitude menores que os LLMs modernos como LLaMA (que pode ter dezenas a centenas de bilhões de parâmetros).
O modelo do artigo, baseado em LLaMA-v3 (8 bilhões de parâmetros na versão utilizada, mas a família LLaMA escala muito mais), aproveita o poder computacional e as capacidades de raciocínio e linguagem aprimoradas de modelos muito maiores. Isso permite que ele lide com nuances médicas e cenários mais complexos de diagnóstico diferencial que modelos menores poderiam ter dificuldade. A capacidade de ajustar um LLM grande com LoRA significa que podemos ter o benefício de um modelo poderoso sem o custo de treinar um do zero, tornando-o mais acessível para implantação local em comparação com a necessidade de licenças caras para modelos proprietários.
LoRA e eficiência de ajuste fino:
A escolha do LoRA como estratégia de ajuste fino é uma vantagem técnica significativa. Outras abordagens, como o ajuste de prompt de instrução usado no Med-PaLM (que adaptou o Flan-PaLM ao domínio médico), são eficientes para certos casos de uso. No entanto, LoRA oferece uma maneira de adaptar o modelo para tarefas específicas sem a necessidade de ajustar todos os bilhões de parâmetros, o que seria computacionalmente inviável para muitas instituições de saúde. Isso permite alto desempenho em tarefas específicas, como diagnóstico diferencial, enquanto atende a requisitos rigorosos de computação e privacidade. O fato de o LLaMA-v3 ser um modelo de código aberto (ou pelo menos com um acesso mais flexível que os modelos proprietários) também é um diferencial, pois permite maior personalização e auditoria.
Explicabilidade:
A inclusão de técnicas de explicabilidade, como a visualização de mapas de autoatenção, é outro ponto forte. Muitos LLMs, especialmente os modelos proprietários maiores, operam como "caixas-pretas". Falei sobre isso aqui. Fornecer insights sobre o processo de tomada de decisão do modelo é vital para construir a confiança de médicos e pacientes, e para cumprir futuras regulamentações sobre IA em saúde. Essa transparência distingue a abordagem do artigo de muitas outras soluções comerciais.
Em resumo, enquanto existem LLMs poderosos na nuvem, a solução apresentada no artigo se destaca por sua combinação de:
- Privacidade e implantação local: Essencial para dados de saúde.
- Poder de um LLM Grande (LLaMA-v3): Capacidade de lidar com complexidade.
- Eficiência de ajuste fino (LoRA): Torna a especialização do modelo prática.
- Explicabilidade integrada: Fomenta a confiança e a compreensão.
Esses fatores a tornam uma solução promissora e mais adequada para o ambiente sensível da saúde do que muitas alternativas baseadas em nuvem, especialmente em cenários onde a soberania dos dados e a conformidade regulatória são inegociáveis.
O caminho à frente e por que isso importa
O trabalho apresentado neste artigo é um passo significativo em direção à criação de soluções de IA mais confiáveis e éticas para a área da saúde. Ao focar na privacidade, no desempenho e na explicabilidade, os autores abordam algumas das maiores preocupações em torno da IA em aplicações médicas.
Para programadores e engenheiros, este trabalho oferece insights valiosos sobre como LLMs podem ser ajustados e implantados de forma responsável em domínios críticos. A combinação de um LLM de código aberto (LLaMA-v3), uma técnica de ajuste fino eficiente (LoRA) e uma interface web local é um blueprint para o desenvolvimento de outras aplicações de IA sensíveis à privacidade.
Olhando para o futuro, os pesquisadores pretendem aprimorar ainda mais a usabilidade e a funcionalidade da plataforma, visando uma análise ainda mais rápida de registros de pacientes para facilitar a detecção precoce e a intervenção oportuna. Este tipo de inovação é crucial para otimizar os fluxos de trabalho clínicos e, o mais importante, melhorar os resultados para os pacientes. A demanda por diagnósticos precisos e oportunos só cresce, e a IA, quando implementada de forma consciente e segura, é a ferramenta que pode nos ajudar a atender a essa demanda.
Referências:
- Artigo base deste post: LLM-Driven Medical Document Analysis: Enhancing Trustworthy Pathology and Differential Diagnosis
- Comparativo de LLMs na Medicina: Comparative analysis of large language models in clinical diagnosis: performance evaluation across common and complex medical cases
- LLMs em Saúde: Desafios e Abordagens: Current applications and challenges in large language models for patient care: a systematic review
Comments