
A verdade indigesta sobre Vibe Coding (com dados)
AIAcha que a IA vai roubar seu emprego de dev? Um novo estudo científico mostra que os modelos mais avançados são ótimos em escrever código... logicamente errado. Entenda por que a IA falha no que realmente importa e o "Vibe Coding" não passa de uma miragem.

Vamos ser honestos. Você já ouviu, e talvez até já tenha sentido um calafrio na espinha. A profecia apocalíptica que ecoa nos corredores do LinkedIn, nos vídeos de "influencers" de tecnologia no YouTube e nas threads intermináveis do Twitter: "A IA vai roubar seu emprego de programador".
A narrativa é sedutora, quase um roteiro de ficção científica. Descreva um aplicativo em linguagem natural, e voilà, uma Inteligência Artificial onipotente cospe um código perfeito, otimizado e livre de bugs. É o nirvana do "Vibe Coding": a ideia de que a engenharia de software, essa disciplina chata e cheia de lógica, pode ser substituída por uma simples conversa, um "feeling", uma... vibe. Você joga a ideia no ar e o gênio digital na garrafa faz o trabalho pesado. Chega de pensar em complexidade de algoritmos, em casos de borda, em gerenciamento de memória. O futuro é só "vibe".
Essa fantasia alimenta o sonho do "programador de 10k" que, na verdade, é só um "engenheiro de prompt". E, para muitos, essa fantasia já virou realidade. Eles apontam para o ChatGPT gerando um script em Python, ou para o Copilot completando uma função, e declaram o fim da era do desenvolvedor humano.
Pois bem. Um grupo de pesquisadores de algumas das universidades mais fodas do planeta (estamos falando de NYU, Princeton, Stanford) resolveu tirar essa história a limpo. Eles pegaram os modelos de linguagem (LLMs) mais avançados do mundo, as joias da coroa da OpenAI, Google e outras, e os colocaram no ringue mais brutal que existe para testar a capacidade de raciocínio lógico em programação: as competições de programação. E o artigo científico que resultou disso, chamado "LiveCodeBench Pro: How do olympiad medalists judge LLMs in competitive programming?", não é apenas um balde de água fria no hype. É um tsunami congelante.
Prepare a pipoca e guarde o seu deboche, porque vamos mergulhar nos dados que provam que a IA, por enquanto, não vai roubar o seu emprego. Na verdade, ela mal conseguiria passar na primeira fase da Olimpíada Brasileira de Informática (OBI).
Bem-vindo à selva da programação competitiva
Antes de olharmos para os resultados deprimentes (para as IAs, claro), você precisa entender onde elas foram testadas. Não estamos falando de criar um site de portfólio em HTML ou um app de lista de tarefas. O benchmark, chamado LiveCodeBench Pro, é baseado em plataformas como Codeforces, ICPC (International Collegiate Programming Contest) e IOI (International Olympiad in Informatics).
Para quem não é da área, deixe-me traduzir:
- IOI é a Copa do Mundo de programação para estudantes de ensino médio. Os problemas são tão absurdamente difíceis que fazem o ENEM parecer um jogo da velha.
- ICPC é a versão universitária, onde equipes das melhores universidades do mundo (MIT, Stanford, etc.) se enfrentam em problemas que exigem um conhecimento profundo de algoritmos e estruturas de dados.
- Codeforces é a plataforma online onde essa galera toda treina. É um moedor de carne para o cérebro, com problemas que variam do "ok, isso é desafiador" ao "que tipo de entidade cósmica maligna inventou isso?".
Os problemas nessas competições são projetados especificamente para serem novos. Eles exigem criatividade, uma observação perspicaz para encontrar um "truque" ou uma sacada genial, e a habilidade de traduzir essa sacada em um código funcional e eficiente em poucas horas. Não é algo que você resolve pesquisando no Stack Overflow. É o teste supremo de raciocínio.
E foi nesse inferno de lógica pura que os pesquisadores jogaram os modelos de IA mais poderosos da atualidade.
As notas das IAs
Vamos direto ao ponto que interessa, a Tabela 1 do artigo. Ela mostra o desempenho dos principais modelos de IA, divididos entre "modelos de raciocínio" (os que usam técnicas como "chain-of-thought" para "pensar" passo a passo) e "modelos sem raciocínio".
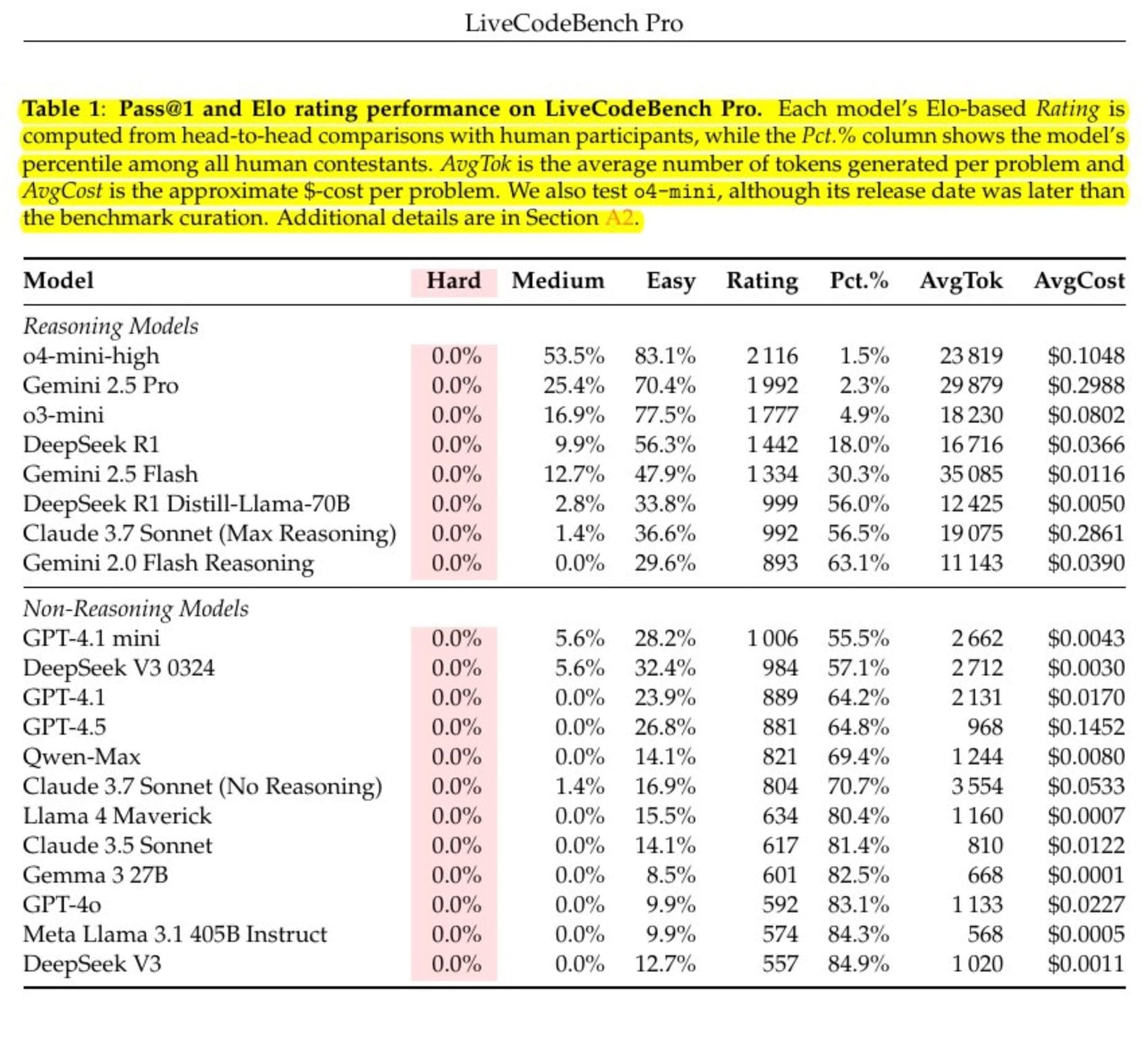
A primeira coisa que salta aos olhos é a coluna "Hard". Repare bem. Uma longa, consistente e gloriosa coluna de 0.0%.
Isso mesmo. ZERO POR CENTO.
Nenhum dos modelos de IA, nem o todo-poderoso o4-mini-high (um modelo de ponta da OpenAI), nem o Gemini 2.5 Pro, conseguiu resolver um único problema da categoria "Difícil".
Imagine contratar um desenvolvedor sênior e descobrir que ele só consegue pegar as tarefas fáceis e médias do Jira. As difíceis? "Ah, não, isso aí eu não sei fazer". Você não o chamaria de sênior. Você o chamaria de desempregado.
Mas vamos com calma antes de coroar nosso novo suserano de silício. Olhemos a coluna "Pct.%", que mostra o percentil do modelo em comparação com todos os competidores humanos. O melhor modelo, o4-mini-high, ficou no percentil 1.5%.
Se você trabalha no marketing de uma empresa de IA, essa é a hora de soltar os fogos. "Nossa IA está no top 1.5% dos programadores humanos de elite!". E, para ser justo, é um feito impressionante. Superar 98.5% dos competidores em uma arena tão difícil não é pouca coisa. O o4-mini-high atinge o nível de "Mestre" (Master), uma patente altíssima no Codeforces.
Só que... aqui mora o diabo nos detalhes. Primeiro, ser um "Mestre" ainda te deixa a anos-luz dos verdadeiros titãs, os "Grandmasters" (top 0.31%) e "Legendary Grandmasters" (top 0.02%), que são os humanos que realmente expandem as fronteiras do que é possível. A IA chegou no topo da pirâmide, mas ainda não consegue nem espiar o pináculo.
E o mais importante: vamos cruzar essa medalha de "Mestre" com a outra informação da tabela. Esse gênio da programação, melhor que 98.5% dos humanos, tirou um retumbante ZERO em TODOS os problemas da categoria "Difícil".
É como ter um lutador de MMA que é campeão mundial, mas que tem uma cláusula no contrato que o impede de lutar contra qualquer um que saiba dar um soco de direita. É um mestre... com um asterisco gigante. Ele é incrível para resolver problemas que se parecem com outros já resolvidos, mas falha miseravelmente quando a tarefa exige uma criatividade genuína para desvendar algo nunca antes visto. A nata da tecnologia de IA é um 'Mestre' de repetição, não um 'Grandmaster' de inovação.E quanto custou essa performance medíocre?
A coluna AvgCost nos dá uma pista. O o4-mini-high custou cerca de 10 centavos de dólar por problema para chegar a essa conclusão de que não sabia resolver. Parece pouco, mas imagine isso em escala, em um sistema complexo. É um custo real para um resultado que, nos casos difíceis, foi literalmente nulo.
Onde a vibe encontra a parede da lógica
Ok, eles são ruins em problemas difíceis. Mas por que eles são ruins? O estudo foi mais fundo e fez uma autópsia dos erros, e é aqui que o conceito de "Vibe Coding" morre de vez.
Uma das descobertas mais espetaculares (Finding 2) foi: "o3-mini comete significativamente mais erros de lógica de algoritmo e observações erradas, e muito menos erros de implementação do que os humanos."

Vamos traduzir essa pérola. Existem dois tipos principais de erros em programação:
- Erros de Implementação: Erros de sintaxe, um ponto e vírgula esquecido, um nome de variável errado, um parêntese faltando. São os erros "bobos", que um bom editor de código ou compilador geralmente pega. É a gramática da programação.
- Erros de Lógica/Conceituais: O código está sintaticamente perfeito. Ele roda. Mas ele faz a coisa errada. O algoritmo está fundamentalmente quebrado. A abordagem para o problema é ingênua ou simplesmente não funciona para todos os casos. É a semântica, o raciocínio, a ideia por trás do código.
As IAs são ótimas na primeira parte. Elas raramente cometem erros de sintaxe. Elas escrevem um código limpo, bem formatado, que parece profissional. O problema é que, na maioria das vezes, esse código lindamente escrito está completamente errado em sua lógica.
É como um aluno que decora o dicionário. Ele pode escrever frases com uma gramática impecável, mas não consegue construir um argumento coerente ou uma história que faça sentido. A IA é esse aluno. Ela sabe como escrever, mas não sabe o que escrever.
A ironia suprema? O "Vibe Coding" promete que você só precisa da ideia ("vibe") e a IA cuida do resto (a implementação). A realidade mostrada pelo estudo é o exato oposto: a IA é boa na parte fácil que já temos ferramentas para resolver (implementação), e péssima na parte difícil que exige um cérebro humano (a ideia, a lógica, o algoritmo).
Para adicionar uma pitada de comédia, o estudo aponta que os modelos frequentemente falhavam nos "exemplos de entrada". Ou seja, eles não conseguiam resolver nem o exemplo mais básico que o próprio enunciado do problema fornecia como um "teste de sanidade". É o equivalente a um chef que não consegue nem cozinhar um ovo.
O monstro do conhecimento vs. o anão da criatividade
Outra descoberta fascinante (Finding 1) revela a dualidade da "inteligência" desses modelos: "LLMs têm um desempenho melhor em problemas pesados em conhecimento e lógica, e pior em problemas pesados em observação ou casos de trabalho."
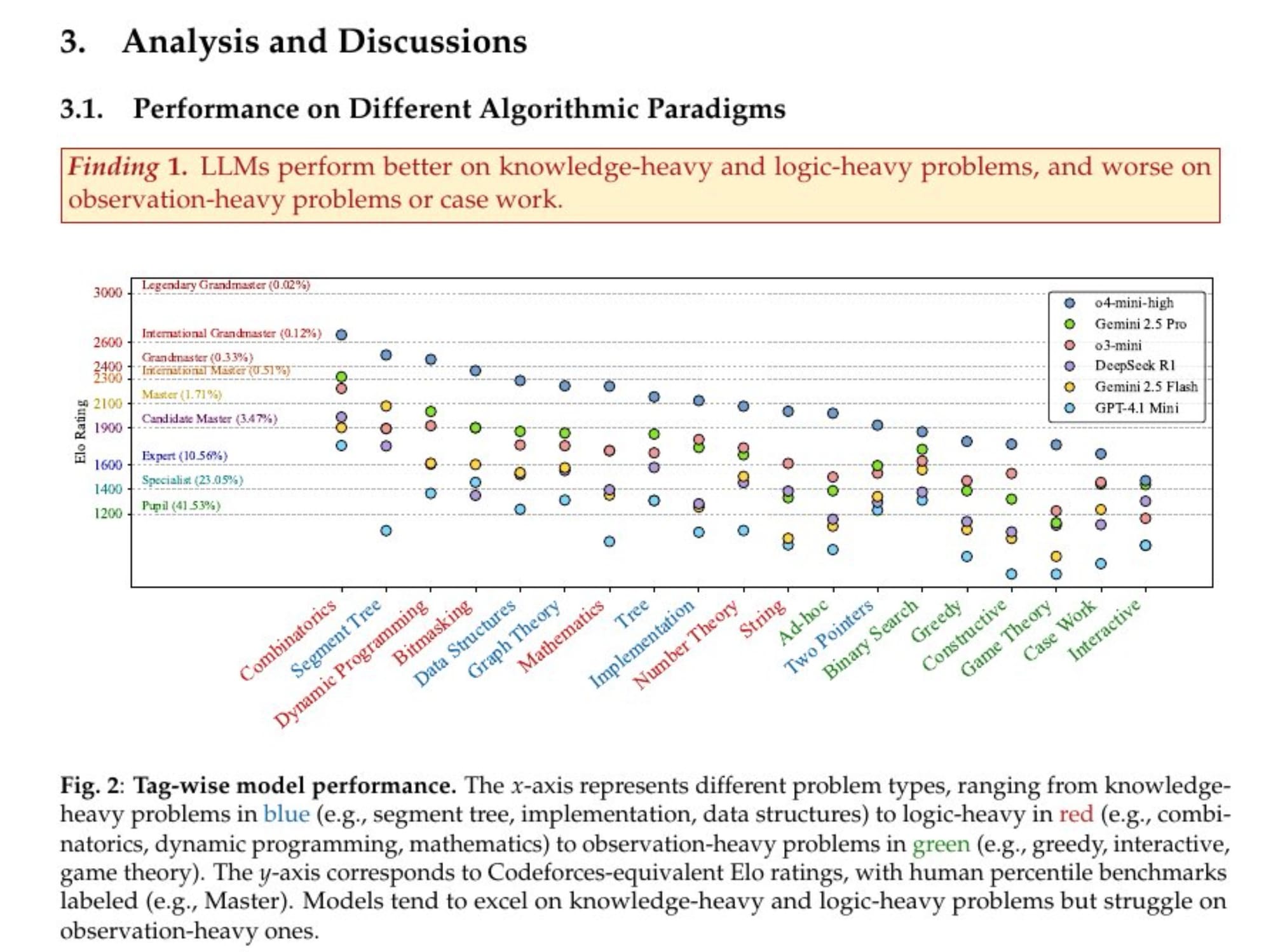
O gráfico acima (Figura 2) é brutalmente claro. Ele mostra o Elo (um sistema de pontuação) dos modelos em diferentes categorias de problemas. As linhas pontilhadas mostram os níveis de competidores humanos: Pupil, Expert, Master, Grandmaster.
Veja o desempenho em categorias como Segment Tree. É um dos melhores desempenhos das IAs. Por quê? Porque Segment Tree é uma estrutura de dados famosa, um tópico de livro didático. É "pesado em conhecimento". A IA já "leu" todos os tutoriais, todos os blogs, todos os livros sobre o assunto. Ela pode regurgitar uma implementação padrão com facilidade. É um exame com consulta a uma biblioteca infinita.
Agora, olhe para o outro lado do espectro. Game Theory (Teoria dos Jogos), Interactive (Problemas Interativos), Greedy (Algoritmos Gulosos, que muitas vezes exigem uma prova ou uma sacada de por que a abordagem funciona). O desempenho despenca. O Elo dos modelos despenca para o nível "Pupil" ou abaixo.
Esses problemas são "pesados em observação". Eles exigem que você encontre um padrão escondido, uma invariante, uma propriedade matemática sutil que é a chave para a solução. Não há um tutorial para isso. Cada problema é um quebra-cabeça único. Requer uma faísca de criatividade, um momento "aha!".
E as IAs não têm momentos "aha!". Elas são máquinas de reconhecimento de padrões em uma escala colossal. Se o problema se parece com algo que elas já viram um milhão de vezes, elas se dão bem. Se o problema requer um pingo de pensamento original, elas entram em colapso. Elas sabem muito, mas pensam muito pouco. Falei sobre isso neste post. E é bom ler esse também depois.
"Deixa eu pensar um pouco...": O raciocínio ajuda? Sim, a falhar com mais estilo.
Os defensores da IA podem argumentar: "Ah, mas você está olhando para os modelos antigos! Os novos 'modelos de raciocínio' são muito melhores!". O estudo também verificou isso. Eles compararam modelos que simplesmente cospem o código (Não-Pensantes) com modelos que geram uma cadeia de pensamentos antes de escrever o código (Pensantes).
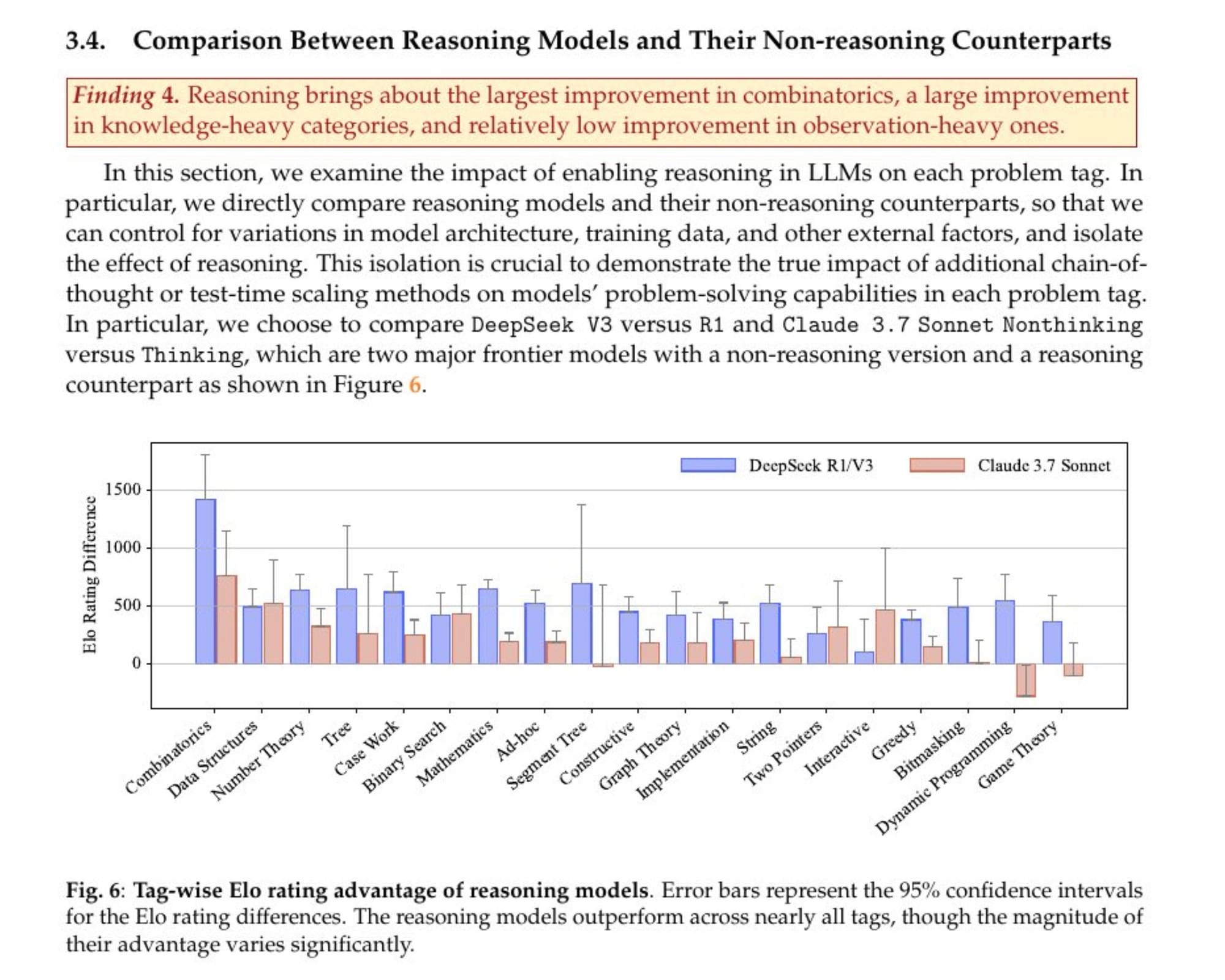
O resultado (Finding 4)? O raciocínio ajuda. O maior ganho de desempenho foi em Combinatorics(Combinatória), uma área notoriamente complexa. O ato de "pensar" passo a passo deu um belo empurrão no desempenho.
Mas aqui entra o deboche. Ajudou a ir de "completamente perdido" para "errado, mas com mais confiança". O "raciocínio" melhorou o desempenho, mas não o suficiente para atravessar a barreira dos problemas difíceis. É a diferença entre tirar um 2 na prova e tirar um 4. É uma melhora, mas você ainda foi reprovado. E, crucialmente, a melhora foi menor justamente naquelas categorias "pesadas em observação". O raciocínio não consegue compensar a falta de criatividade.
Atirando para todos os lados
Existe mais uma métrica interessante no estudo: a diferença entre pass@1 e pass@10.
pass@1: O modelo acertou o problema na primeira tentativa.pass@10: O modelo acertou o problema em até 10 tentativas.
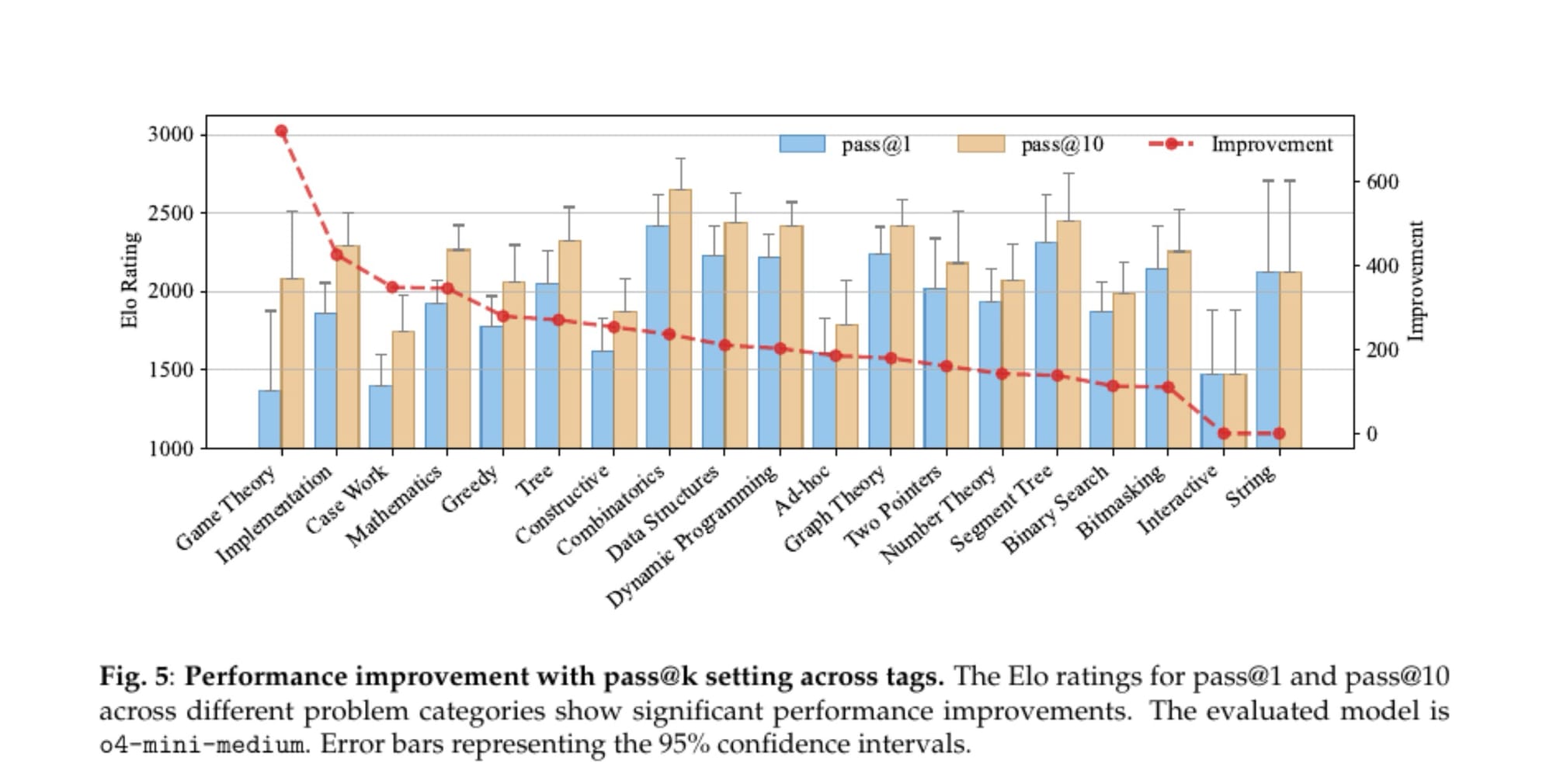
O gráfico mostra que o desempenho melhora significativamente quando se dá mais tentativas à IA. Isso soa bem, até você pensar no que isso significa. Um bom programador não escreve 10 versões completamente diferentes de um programa na esperança de que uma funcione. Um bom programador pensa, depura, refina e itera sobre uma solução.
A IA, por outro lado, está usando a "metralhadora". Ela gera uma série de soluções levemente diferentes, muitas vezes sem uma compreensão real do porquê a anterior falhou, e espera que uma delas magicamente passe nos testes. Isso não é inteligência. É força bruta estatística. É ineficiente, caro e um pesadelo para depurar. É o oposto de engenharia.
O problema é ainda maior
Este estudo foca em problemas de competição, que são autocontidos e bem definidos. No mundo real da engenharia de software, o buraco é muito mais embaixo.
- Segurança: Inúmeros estudos já mostraram que o código gerado por IAs é frequentemente um queijo suíço de vulnerabilidades de segurança. Elas replicam padrões de código inseguros que encontram em seus dados de treinamento (olá, injeção de SQL!) porque não têm um conceito real de "segurança".
- Manutenção e "código alien": O código de uma IA pode ser difícil de entender e manter. Ele não vem com o contexto, as decisões de design, as trocas que um desenvolvedor humano considera. É um "código alienígena" que aparece no seu repositório. Se ele quebrar, boa sorte para descobrir o "raciocínio" da máquina.
- A tirania da janela de contexto: Modelos de IA só conseguem "lembrar" de uma quantidade limitada de texto (a janela de contexto). Um projeto de software real tem milhões de linhas de código, dependências complexas e uma lógica de negócios que evoluiu por anos. Nenhuma IA hoje consegue absorver o contexto de um sistema real para fazer uma mudança significativa e segura. Os problemas do LiveCodeBench, por mais difíceis que sejam, são um playground comparado a isso.
- O viés dos dados de treinamento: As IAs são inerentemente conservadoras. Elas são excelentes em recriar soluções para problemas que já foram resolvidos milhares de vezes. A verdadeira engenharia, no entanto, acontece quando você enfrenta um problema novo, que exige uma arquitetura nova. É aí que a inovação acontece, e é aí que as IAs, por definição, falham.
Para que serve então o "Vibe Coding"?
Depois de tudo isso, parece que estou dizendo que as IAs são inúteis para programação. Não é verdade. Seria tolice ignorar o poder dessas ferramentas. A questão é entender qual é o seu lugar.
As IAs não são o arquiteto sênior ou o desenvolvedor principal. Elas são o melhor estagiário que o dinheiro pode comprar. São um "copiloto" fantástico.
Elas são excelentes para:
- Escrever código repetitivo (boilerplate): Configurar um servidor web básico, criar os componentes de uma API REST, etc.
- Gerar testes unitários: Elas podem olhar para uma função e gerar uma bateria de testes básicos, economizando um tempo precioso.
- Tradução de linguagens: "Converta este código em Python para Go."
- Explicação de código: "O que esta função Regex faz?"
- Prototipagem rápida: Esboçar ideias e testar conceitos rapidamente.
Elas são uma ferramenta de produtividade, um canivete suíço para o desenvolvedor. Elas aceleram as partes mecânicas do trabalho, liberando o cérebro humano para focar no que realmente importa: a arquitetura do sistema, a lógica de negócios complexa e a resolução de problemas difíceis e inéditos.
Conclusão: seu emprego está seguro, mas ele vai mudar
Então, da próxima vez que você vir um post no LinkedIn proclamando a morte do programador, respire fundo e sorria. A ciência rigorosa, conduzida por especialistas e testada no ambiente mais desafiador possível, nos deu um veredito claro.
O "Vibe Coding" é uma miragem. A essência da programação nunca foi sobre digitar; sempre foi sobre pensar. E as IAs, por mais que sejam impressionantes em manipular texto, ainda estão a anos-luz de distância de replicar o raciocínio criativo, a observação perspicaz e a lógica profunda que definem um bom engenheiro de software.
O estudo 'LiveCodeBench Pro' nos mostra que o imperador da IA, embora vestido com roupas deslumbrantes de marketing, está surpreendentemente nu quando se trata de inteligência algorítmica de verdade. O modelo mais avançado pode até superar 98% dos competidores humanos, um feito digno de nota, mas essa mesma 'inteligência' de elite se desfaz completamente diante de um problema verdadeiramente difícil, falhando em 100% das vezes. Eles são ótimos em escrever código que é sintaticamente perfeito mas logicamente falho, e sua principal habilidade parece ser a de regurgitar conhecimento existente, não criar novo.
A ameaça real não é a IA substituindo os desenvolvedores. É os desenvolvedores que se recusam a usar a IA como uma ferramenta serem superados por aqueles que a usam para automatizar o tédio e focar na criatividade.
Portanto, relaxe. O seu trabalho não vai desaparecer. Mas a barra vai subir. O futuro não pertence a quem sabe "conversar" com uma IA, mas a quem sabe pensar de forma tão crítica e criativa que pode usar a IA para construir algo genuinamente novo e robusto.
Agora, se me dão licença, tenho um problema de lógica aqui que nenhuma IA no planeta consegue resolver por mim. E, honestamente, ainda bem. É a parte mais divertida do trabalho.
Comments