
A Ilusão de Controle: Detectores de IA são uma fraude
AIEu já havia escrito sobre isso 6 meses atrás. Mas agora tem um estudo científico corroborando o que eu já sabia e já tinha afirmado.

Há seis meses, eu publiquei aqui no blog um artigo que gerou bastante discussão: A Fraude dos Detectores Textuais de IA. Naquela época, eu usei minha experiência de mais de 20 anos desenvolvendo software e liderando times para argumentar que essas ferramentas eram, na melhor das hipóteses, "óleo de cobra" digital e, na pior, máquinas de gerar injustiça.
Eu afirmei que tentar detectar texto gerado por IA usando estatística reversa era uma batalha perdida. Recebi alguns e-mails de colegas e gestores preocupados, dizendo que eu estava sendo "radical", que a tecnologia iria evoluir e que "precisamos de ferramentas de controle".
Pois bem. A ciência chegou para o debate. E ela não trouxe boas notícias para quem vende essa ilusão de controle.
Recentemente, me deparei com um estudo robusto publicado no International Journal of Educational Technology in Higher Education, conduzido por Mike Perkins e sua equipe. Eles não fizeram apenas uma opinião de blog como a minha; eles aplicaram o método científico para testar a eficácia dessas ferramentas contra técnicas simples de evasão.
O resultado? É pior do que eu imaginava. Se você acha que está seguro pagando licenças caras do Turnitin ou Copyleaks, convido você a ler as próximas linhas. Vamos olhar o que acontece debaixo do capô dessas ferramentas quando confrontadas com a realidade.
O estudo
O estudo “Simple techniques to bypass GenAI text detectors” fez o que todo bom engenheiro de QA (Quality Assurance) faria: testou o "caminho infeliz". Eles não pegaram apenas o texto cru do ChatGPT e jogaram no detector. Eles simularam o mundo real, onde estudantes e profissionais usam a IA como ferramenta de apoio e edição.
Eles testaram 805 amostras de texto usando ferramentas como GPT-4, Gemini e Claude, contra os detectores mais famosos do mercado: Turnitin, GPTZero, Copyleaks, entre outros.
O cenário base já é assustador. Quando o texto gerado por IA não foi manipulado, a precisão média dos detectores foi de apenas 39,5%.
Pare e pense nisso como um engenheiro. Se eu entregasse um sistema de autenticação ou um firewall que funciona menos de 40% das vezes, eu seria demitido por justa causa antes do almoço. Mas na educação e na contratação, estamos aceitando isso como "padrão de indústria".
Vulnerabilidade ridícula
Onde a coisa fica realmente interessante (e cômica, se não fosse trágica) é quando aplicamos as chamadas "técnicas adversariais". O nome soa complexo, coisa de hacker de filme, mas na prática são ajustes manuais que qualquer pessoa faz.
O estudo mostrou que a precisão dos detectores cai vertiginosamente quando você aplica técnicas simples. Veja esta tabela extraída do estudo:
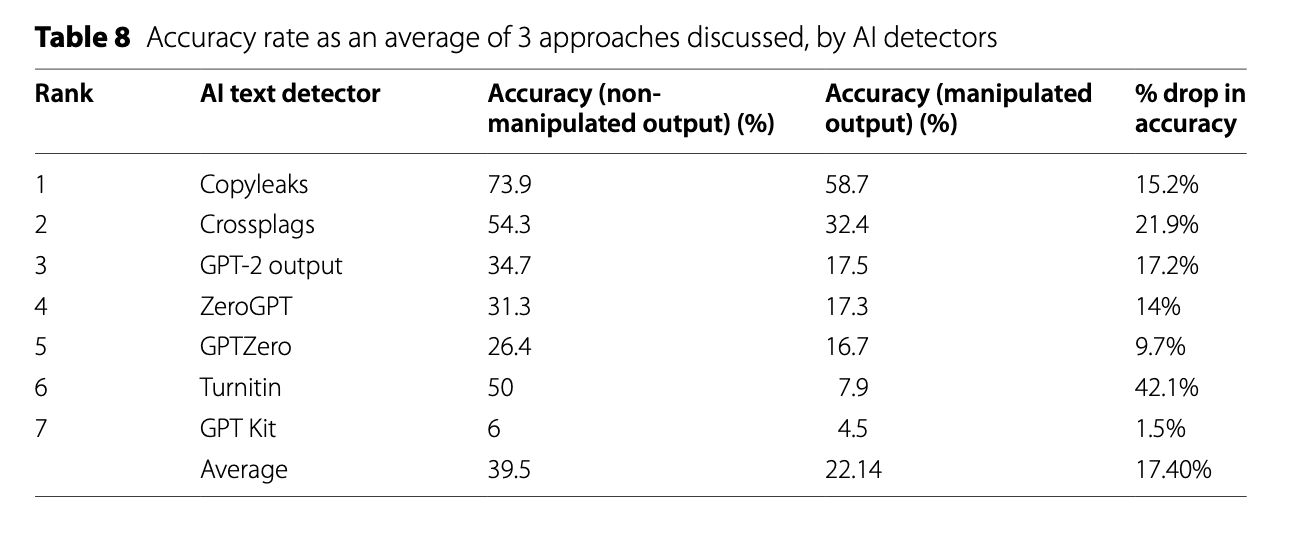
Note o Turnitin. Ele é considerado o "padrão ouro" nas universidades. A precisão dele caiu 42,1% quando o texto foi manipulado. Ele passou de uma ferramenta questionável para um gerador de números aleatórios.
Mas qual foi a técnica sofisticada de hacking usada? Injeção de SQL? Engenharia reversa de tokens?
Não. Eles pediram para a IA inserir erros de ortografia ou variar o tamanho das frases (o que chamamos tecnicamente de burstiness).
"Resultados mostram reduções significativas na precisão do detector (17,4%) quando confrontado com técnicas simples para manipular o conteúdo gerado por IA."
Quando o estudo aplicou a técnica de "Adicionar Erros de Ortografia" (Spelling Errors), a detecção média caiu para 12,9%. Ou seja, a ferramenta de "segurança" foi derrotada porque o texto parecia mal escrito. Isso expõe a fragilidade desses algoritmos: eles buscam a perfeição estatística dos LLMs (Large Language Models). Se você "sujar" o texto, a máquina assume que foi um humano (imperfeito) que escreveu.
Uma máquina de acusar inocentes
Como alguém que trabalha com tecnologia há duas décadas, o que mais me irrita não é o software falhar em detectar a IA (falso negativo). O que me tira o sono é o falso positivo. É o software acusar um humano de ser um robô.
O estudo de Perkins trouxe um dado alarmante sobre o Copyleaks, que muitas vezes é vendido como o detector mais preciso do mercado. Embora ele tenha detectado melhor os textos de IA, ele teve uma taxa de falso positivo de 50% em amostras escritas por humanos.
Você leu certo. Em metade dos casos onde um humano escreveu o texto, o Copyleaks disse que era IA. Imagine o impacto disso na vida de um estudante ou de um candidato a uma vaga de emprego. Ser falsamente acusado de fraude por um algoritmo proprietário, caixa-preta, que você não pode auditar.
Isso nos leva a um ponto que toco frequentemente aqui no blog: o impacto humano da tecnologia mal aplicada.
O viés contra não-nativos (Inclusividade)
O estudo destaca que detectores de IA são inerentemente tendenciosos contra falantes não nativos de inglês (NNES - Non-Native English Speakers).
Por que isso acontece? Vamos falar de Perplexidade.
LLMs funcionam prevendo a próxima palavra mais provável. Textos com "baixa perplexidade" são textos previsíveis, estatisticamente "médios". Falantes nativos de uma língua costumam usar gírias, estruturas complexas e imprevisíveis (alta perplexidade).
Nós, que aprendemos inglês (ou qualquer segunda língua) de forma acadêmica, tendemos a escrever de forma mais estruturada, gramaticalmente correta e... previsível. Para um detector burro, meu inglês técnico soa muito parecido com o inglês do ChatGPT.
O estudo alerta explicitamente:
"Pesquisas mostraram que detectores de texto GenAI têm o potencial de ser barreiras para práticas de avaliação inclusivas, visando desproporcionalmente indivíduos que não falam inglês como primeira língua."
Estamos criando um sistema onde escrever "corretamente demais" é suspeito. É a penalização da competência técnica em prol de uma "humanidade" caótica que a máquina espera.
Por que isso não vai melhorar
Alguns vão dizer: "Ah, mas o GPT-6 vai resolver isso" ou "O Turnitin vai lançar um patch semana que vem".
Baseado no que sei sobre como LLMs funcionam, eu digo: não vai. Estamos vivendo um jogo de gato e rato onde o gato está ficando gordo e lento, e o rato virou um ciborgue.
- A natureza dos modelos: Os modelos de IA estão sendo treinados para serem mais humanos. O objetivo da OpenAI, Google e Anthropic é reduzir a alucinação e aumentar a naturalidade. Quanto melhor a IA fica, mais difícil é detectá-la matematicamente. O estudo mostrou que o Claude já era mais difícil de detectar que o Gemini. E já estamos no Claude 4.5 e GPT-5.
- O problema da caixa preta: Empresas como Turnitin e Copyleaks não abrem seu código. Nós temos que confiar na palavra deles de que "a precisão é de 99%". O estudo independente de Perkins, no entanto, mostra a realidade nua e crua. Como engenheiros, sabemos que segurança por obscuridade não funciona.
- A facilidade do bypass: Como vimos, não precisa ser um hacker. Um simples prompt "Reescreva isso como um aluno de ensino médio com pressa" já quebra a detecção.
O que devemos fazer?
Se você é gestor, professor ou líder técnico, minha recomendação continua a mesma de 6 meses atrás, agora reforçada por dados acadêmicos: pare de usar essas ferramentas para policiamento.
O estudo conclui de forma inteligente:
"Devido às limitações de precisão e ao potencial de falsa acusação... elas não podem ser recomendadas atualmente para determinar violações de integridade acadêmica."
Eles sugerem usar essas ferramentas, se muito, de forma não punitiva, para iniciar diálogos. Mas, honestamente? Eu acho que nem para isso servem. Se a ferramenta é um gerador de cara ou coroa, ela não serve para basear diálogo nenhum.
Conclusão
A tentativa de controlar a GenAI com software de detecção é uma reação de pânico, não uma estratégia técnica. É a busca por uma bala de prata que não existe.
Em vez de gastar orçamento com licenças de software que acusam seus melhores alunos ou funcionários estrangeiros de serem robôs, gaste tempo repensando como você avalia competência.
Se um júnior no meu time usa o Copilot para escrever um código e o código funciona, é seguro e performático, eu não me importo se foi a IA. Eu me importo se ele entende o que o código faz. A avaliação mudou. Deixamos de avaliar a sintaxe (escrever o código/texto) para avaliar a semântica (o significado e o valor do resultado).
A fraude não está no uso da IA. A fraude está em vender a ideia de que podemos distinguir matematicamente a criatividade humana da máquina com 100% de certeza. A ciência provou que não podemos.
E você? Ainda confia no selo "0% AI" do seu detector favorito ou está pronto para aceitar que a forma como trabalhamos mudou para sempre?
Este artigo foi escrito por um humano. Ou será que foi? Segundo o Copyleaks, talvez haja 50% de chance de eu não existir.
Comments