
A IA está transformando o diagnóstico médico iterativo e eficiente
Bio-MedicinaUm novo modelo da MIcrosoft AI superou (e muito) médicos experientes em diagnóstico de doenças complexas. E ainda gastando menos. Leia neste artigo sobre o SDBench e seu modelo MAI-DxO.

Sempre que a gente fala de inteligência artificial na medicina, a imagem que vem à mente é de algo futurista, quase de filme. Mas a realidade já está bem mais próxima, e um estudo recente da Microsoft AI mostra como a IA pode não só expandir o acesso ao conhecimento médico, mas também aprimorar o raciocínio diagnóstico de forma que nem um médico sozinho consegue. A grande sacada é simular o processo de raciocínio clínico iterativo, algo que vai muito além de dar uma resposta de múltipla escolha.
O desafio do diagnóstico sequencial no mundo real
Na prática clínica, um médico não recebe todas as informações de uma vez. É um processo dinâmico: ele ouve a queixa principal, faz perguntas, pede exames, avalia os resultados e, a cada nova informação, refina suas hipóteses diagnósticas. É um vai e vem de informações, onde cada passo conta, tanto para a precisão quanto para o custo e o conforto do paciente.
Atualmente, a maioria das avaliações de Modelos de Linguagem (LMs) para diagnóstico médico se baseia em cenários estáticos, tipo uma prova de múltipla escolha. Nesses testes, o modelo recebe um resumo completo do caso e precisa selecionar uma doença de uma lista predefinida. Isso é como dar a resposta para o aluno antes da pergunta. Embora LMs já tenham mostrado performance impressionante em exames médicos e vinhetas estruturadas, essas condições artificiais não refletem a complexidade do mundo real. Um modelo avaliado assim pode, por exemplo, fechar um diagnóstico prematuramente, pedir exames indiscriminadamente ou ficar preso a uma hipótese inicial – coisas que um médico experiente tenta evitar.
É por isso que o novo benchmark, chamado Sequential Diagnosis Benchmark (SDBench), é tão relevante. Ele transforma 304 casos desafiadores do New England Journal of Medicine Clinicopathological Conference (NEJM-CPC) em encontros diagnósticos passo a passo. Basicamente, é uma simulação onde um médico (ou uma IA) começa com um resumo curto do caso e precisa ir pedindo mais detalhes para um "Gatekeeper" – um modelo que só revela informações quando explicitamente perguntado. A performance não é só avaliada pela precisão do diagnóstico, mas também pelo custo das consultas e exames solicitados. Isso é fundamental, pois alinha a avaliação com o conceito de "Triple Aim" da saúde: alta qualidade de cuidado com custo sustentável.
Detalhando o SDBench
Para construir o SDBench, os pesquisadores pegaram esses casos do NEJM, que abrangem desde condições comuns (tipo "Pneumonia por Covid-19") até doenças raras (como "Hipoglicemia neonatal devido a teratoma biologicamente ativo"). Cada um desses 304 casos, publicados entre 2017 e 2025, virou uma simulação interativa de raciocínio diagnóstico sequencial.
Funciona assim: a sessão começa com um breve resumo do paciente e sua queixa principal. Por exemplo: "Uma mulher de 29 anos foi internada por dor de garganta, inchaço peritonsilar e sangramento. Os sintomas não melhoraram com a terapia antimicrobiana". A partir daí, o agente de diagnóstico (seja humano ou IA) tem três ações possíveis:
- Fazer perguntas: Perguntas de texto livre sobre o histórico ou detalhes do exame ("Ela viajou recentemente?"). Múltiplas perguntas são permitidas.
- Solicitar exames de diagnóstico: Pedidos explícitos de exames laboratoriais, de imagem ou procedimentos ("Pedir uma tomografia de tórax com contraste").
- Diagnosticar: Um compromisso único com um diagnóstico final ("O diagnóstico é histoplasmose").
O "Gatekeeper" (também um LM, no caso, o GPT-4o-mini) interpreta cada solicitação, consulta o prontuário completo do caso e responde em linguagem natural, fornecendo a informação pedida ou recusando se a pergunta for muito vaga. Se o agente de diagnóstico decidir "diagnosticar", um "Judge" (outro LM, o GPT-4o) avalia a correção do diagnóstico proposto, e um "Cost Estimator" calcula o custo total de todos os exames solicitados.

O Gatekeeper foi projetado para ser muito realista. Ele só divulga informações que um médico real conseguiria, evitando dar "spoilers" ou dicas que não estariam disponíveis numa consulta genuína. Por exemplo, exames de imagem são retidos até serem explicitamente solicitados, e achados patognomônicos (aqueles que praticamente fecham um diagnóstico) só são revelados se o teste confirmatório exato for pedido.
Uma coisa legal que eles fizeram para manter o realismo foi, em vez de responder "Não disponível" para informações que não estavam no caso original do NEJM, o Gatekeeper retorna achados sintéticos realistas. Isso evita que o agente de diagnóstico perceba "pistas" implícitas e garante que ele continue explorando caminhos de raciocínio válidos. Essa abordagem foi validada por um painel de médicos que revisou as respostas do Gatekeeper e encontrou pouquíssimos problemas.
O "Judge" também é um componente crucial. Como dois médicos podem descrever a mesma condição com terminologias diferentes, mas chegar ao mesmo tratamento, o Judge avalia os diagnósticos com base na substância clínica, e não apenas nas palavras. Ele usa uma rubrica detalhada, criada por médicos, que considera a doença principal, etiologia, local anatômico, especificidade e completude. Para um diagnóstico ser considerado "correto", ele precisa atingir uma pontuação de ≥4 em uma escala Likert de cinco pontos, o que significa que a conduta clínica seria praticamente inalterada. A validação mostrou uma alta concordância entre o Judge automatizado e médicos humanos.
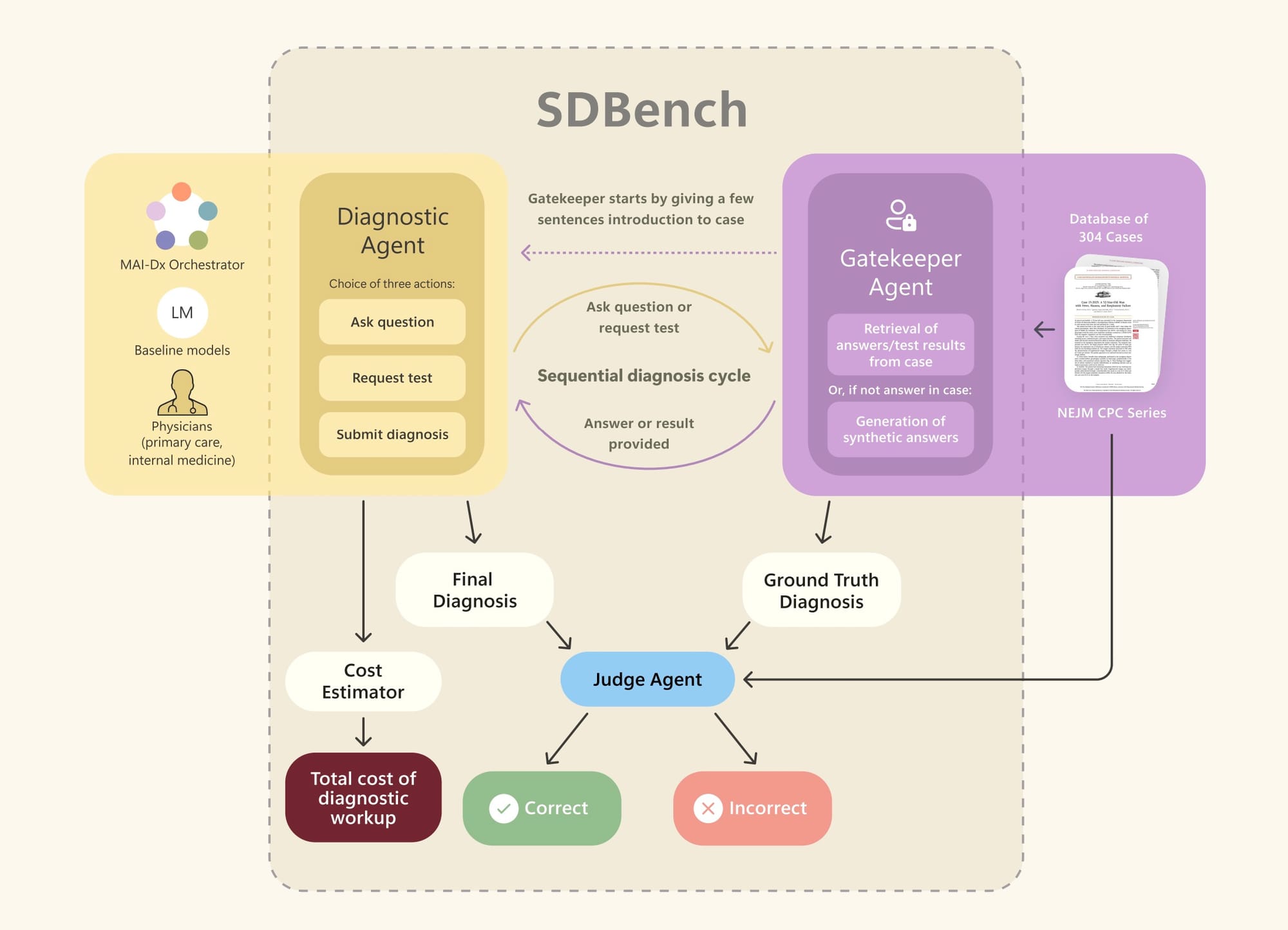
E, claro, o custo. Medir o custo monetário dos exames é uma forma de desincentivar comportamentos irrealistas, como pedir tudo que se possa imaginar. Na prática, um médico precisa equilibrar o benefício diagnóstico de um exame com seu custo, invasividade, tempo para o resultado e limitações de convênio. Eles atribuíram um custo fixo de $300 por visita médica (que inclui várias perguntas sequenciais). Os custos dos exames diagnósticos foram determinados usando um sistema baseado em LM que traduzia os pedidos de texto livre em códigos CPT (Current Procedural Terminology) e depois associava esses códigos a uma tabela de preços de um grande sistema de saúde dos EUA. Mesmo não sendo uma representação exata dos custos reais, é uma forma padronizada e consistente de comparar a eficiência de diferentes agentes.
MAI-DxO
A grande estrela do estudo é o MAI Diagnostic Orchestrator (MAI-DxO). É um sistema orquestrado, co-desenvolvido com médicos, que supera tanto os médicos humanos quanto os LMs comerciais. Em vez de usar um LM "cru", o MAI-DxO simula um painel de médicos virtuais, que propõe diagnósticos diferenciais prováveis e seleciona estrategicamente os testes mais valiosos e com melhor custo-benefício.
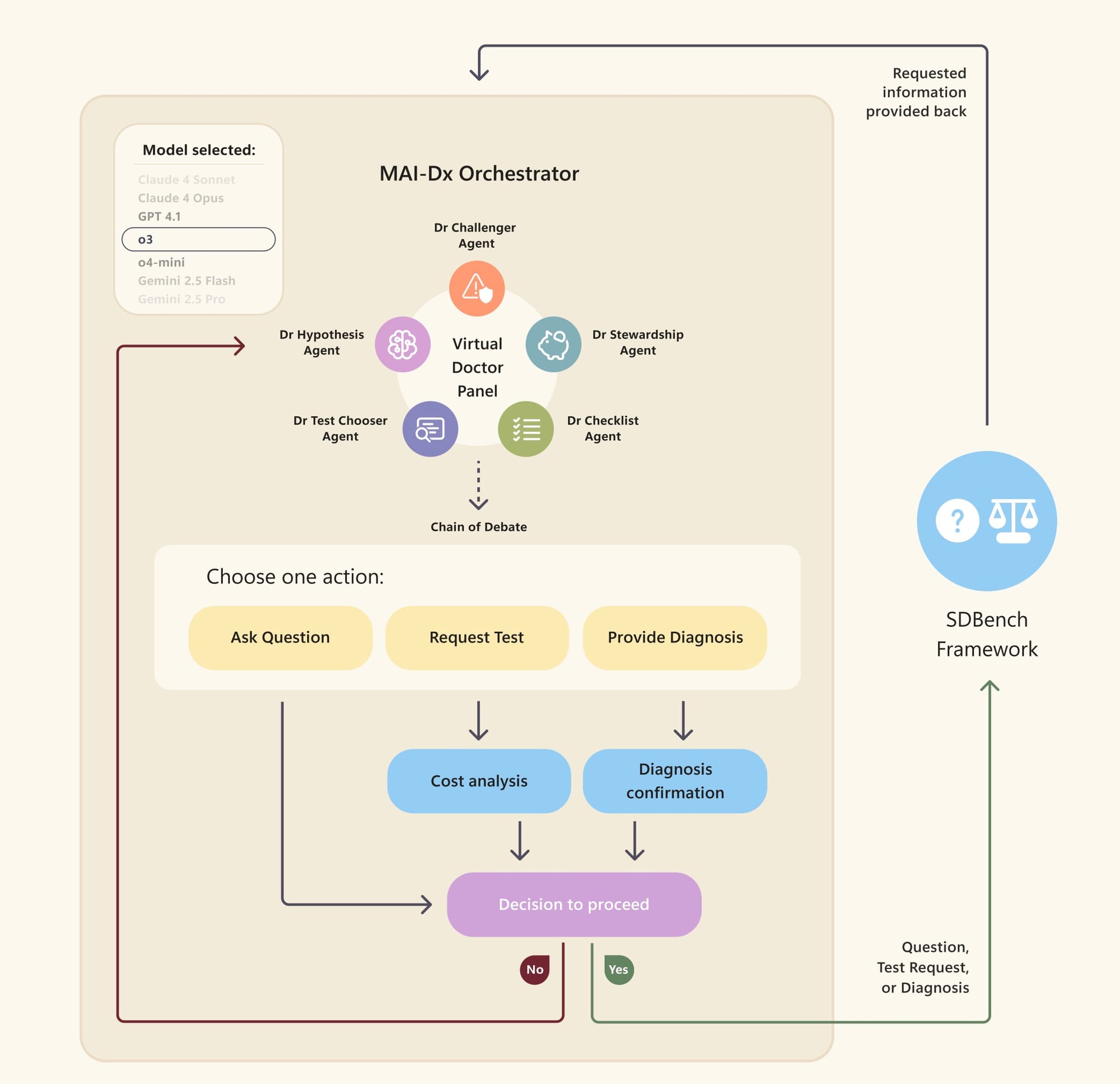
Esse painel virtual consiste em cinco papéis especializados:
- Dr. Hipótese: Mantém uma lista de diagnósticos diferenciais, ranqueados por probabilidade, atualizando-os de forma Bayesiana a cada nova informação.
- Dr. Selecionador de Testes: Escolhe até três exames por rodada que melhor discriminam entre as principais hipóteses.
- Dr. Desafiador: Atua como "advogado do diabo", identificando vieses, destacando evidências contraditórias e propondo testes que poderiam refutar o diagnóstico principal. Essa é uma das sacadas mais importantes do sistema para evitar a "ancoragem" que os modelos puros podem sofrer.
- Dr. Custo-Eficiência (Stewardship): Promove o cuidado consciente com os custos, sugerindo alternativas mais baratas quando clinicamente equivalentes e vetando exames caros e de baixo rendimento.
- Dr. Checklist: Realiza um controle de qualidade silencioso, garantindo que o modelo gere nomes de testes válidos e mantenha a consistência interna no raciocínio do painel.
Após uma "deliberação interna", o painel chega a um consenso sobre uma das três ações: fazer perguntas, pedir exames ou dar um diagnóstico final (se a certeza exceder um certo limite). Antes de pedir exames, um sistema opcional de orçamento pode ser acionado para estimar os custos acumulados e o custo de cada novo exame, permitindo que o painel cancele testes se o custo for alto demais.
Eles testaram cinco variantes do MAI-DxO para explorar o balanço entre precisão e custo:
- Resposta Imediata (Instant Answer): Diagnóstico baseado apenas na descrição inicial, sem perguntas ou testes adicionais.
- Apenas Perguntas (Question Only): O painel pode fazer perguntas, mas não pode pedir exames. O custo é apenas o de uma consulta médica.
- Com Orçamento (Budgeted): O painel tem um sistema de orçamento que rastreia os custos acumulados e permite cancelar testes.
- Sem Orçamento (No Budget): Painel completo, sem rastreamento explícito de custos ou limitações de orçamento.
- Conjunto (Ensemble): Simula múltiplos painéis de médicos trabalhando em paralelo, com um painel adicional para fornecer o diagnóstico final. Os custos são a soma dos custos de todos os testes pedidos por cada painel.
Apesar de ter sido otimizado principalmente com o GPT-4.1, o MAI-DxO é "agnóstico ao modelo". Isso significa que sua estrutura de raciocínio orquestrado pode ser aplicada a outros LMs, o que é uma vantagem e tanto para a interoperabilidade e para não ficar preso a um fornecedor.
Resultados: IA supera médicos (e muito) em diagnóstico complexo
Os resultados são impressionantes e, diria, até um pouco assustadores para quem não acompanha de perto o avanço da IA.
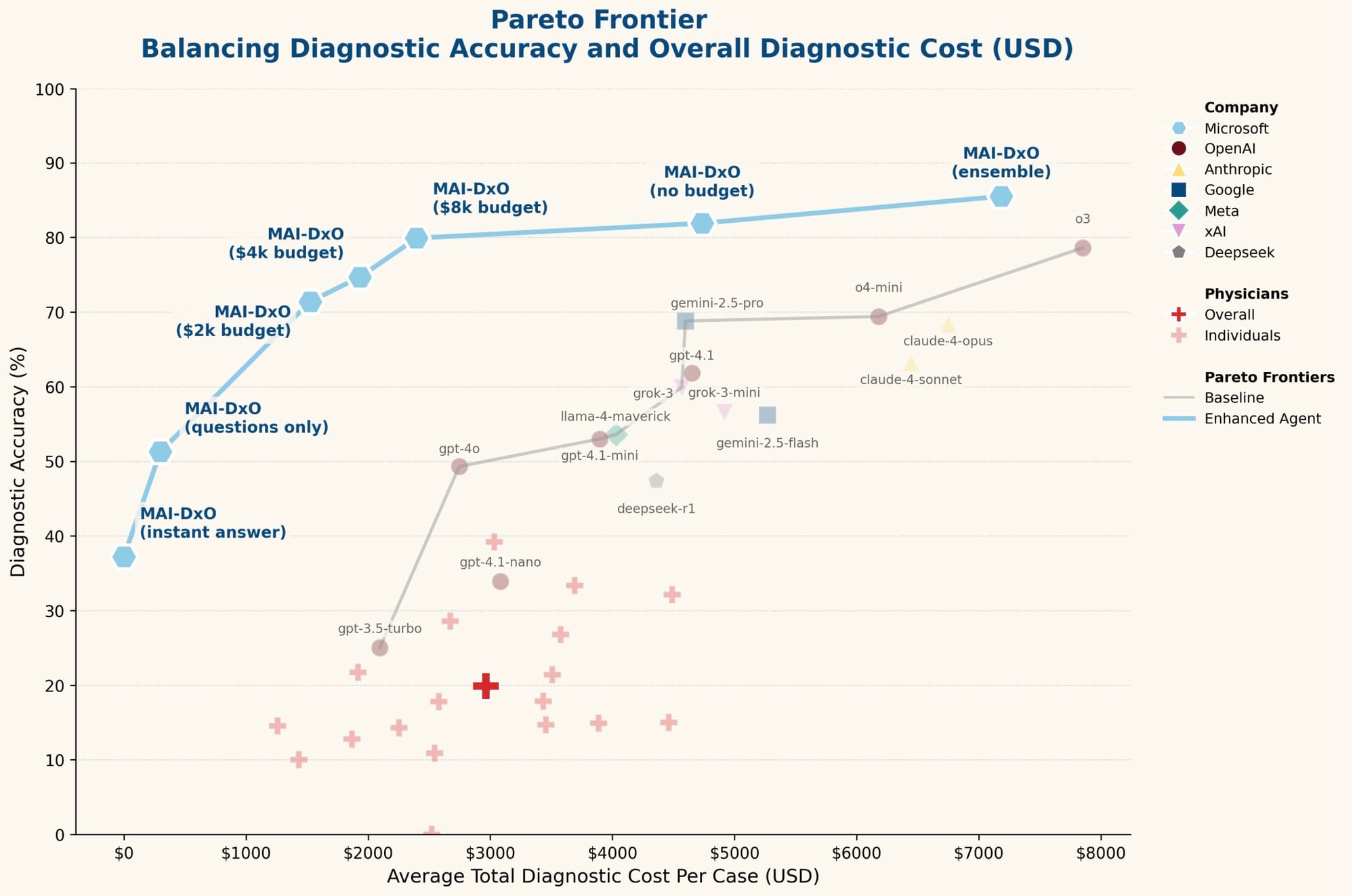
A figura acima, a "fronteira de Pareto", mostra a relação entre a precisão diagnóstica e o custo. Cada ponto representa a performance de um agente de IA. Os médicos (representados pelos sinais de mais) tiveram uma precisão média de 19,9% com um custo médio de $2.963 por caso. Isso reforça a dificuldade dos casos do NEJM, que são selecionados justamente por serem complexos e desafiadores, mesmo para médicos experientes.
Modelos de LM "puros" (off-the-shelf) mostraram um trade-off: maior precisão geralmente vinha com maior custo. O GPT-4o, por exemplo, alcançou 49,3% de precisão com custo de $2.745. Já o GPT 03, atingiu 78,6% de precisão, mas com um custo de $7.850. Isso mostra que, mesmo para as IAs mais avançadas, a coleta de informações é crucial, e quanto mais informações, mais precisão (e custo).
Aí entra o MAI-DxO (a curva azul). Ele simplesmente estabelece uma nova fronteira de Pareto, superando os modelos "puros" e os médicos em todos os níveis de custo ou precisão. A configuração padrão do MAI-DxO (sem orçamento), usando o GPT-4o como base, atingiu 81,9% de precisão, enquanto reduziu os custos médios dos testes para $4.735 (comparado aos $7.850 do GPT o3 puro). Isso é um salto: melhorou a precisão e cortou o custo pela metade.
Quando configurado para máxima precisão, usando técnicas de ensembling, o MAI-DxO alcançou 85,5% de precisão, mantendo os custos em $7.184 – ainda abaixo do GPT o3 puro. Para ter uma ideia, isso é quatro vezes mais preciso que a média dos médicos generalistas. E em uma configuração focada em custo, o MAI-DxO conseguiu 79,9% de precisão por apenas $2.396. Isso é uma das coisas que me deixa com a pulga atrás da orelha: a gente tá falando de um sistema que consegue ser muito melhor em custo-benefício que médicos experientes.
Um caso de exemplo ilustra bem isso: um paciente hospitalizado por abstinência de álcool, que ingeriu álcool em gel. O GPT o3 puro fixou na toxicidade por antibióticos, pedindo exames caros (incluindo ressonância do cérebro e EEG) e deu um diagnóstico incorreto com custo de $3.431. Já o MAI-DxO, com seu Dr. Hipótese e Dr. Desafiador, levantou a hipótese de exposição a toxinas hospitalares logo na primeira rodada e perguntou sobre a ingestão de álcool em gel. Essa pergunta direta levou à confissão do paciente, a testes específicos (painel de álcoois tóxicos) e um diagnóstico correto com custo de apenas $795. É uma prova de que a orquestração de raciocínio é um diferencial enorme.
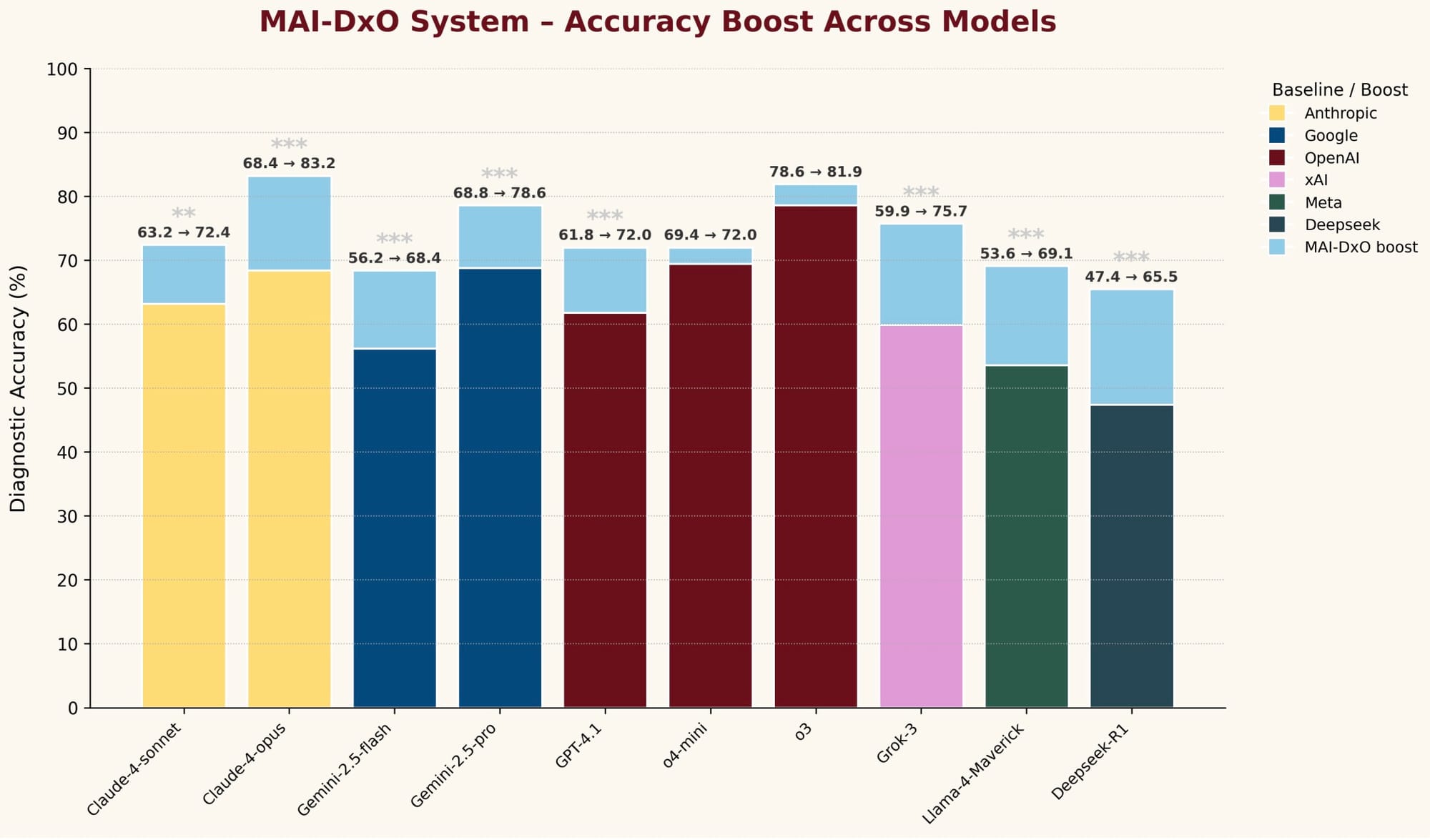
Outro ponto fundamental, como já disse anteriormente, o MAI-DxO é agnóstico ao modelo. Mesmo tendo sido desenvolvido com o GPT-4.1, ele melhorou a precisão diagnóstica de todos os modelos de fundação testados, com ganhos mais expressivos para os que tinham uma performance de linha de base mais baixa. Isso sugere que a estrutura de raciocínio do MAI-DxO ajuda modelos mais fracos a superar suas limitações através de um raciocínio estruturado. Para modelos mais capazes, o MAI-DxO impõe uma disciplina útil, garantindo diferenciais abrangentes, reduzindo o viés de ancoragem e incentivando testes conscientes em relação ao custo. É como se ele "override" alguns vieses que os modelos podem ter na sua configuração padrão para usos gerais.
A robustez dos resultados também foi testada em um conjunto de casos de "teste oculto", com 56 casos publicados entre 2024 e 2025 que não foram vistos durante o desenvolvimento. O MAI-DxO manteve sua performance e as melhorias relativas, mostrando que os ganhos não são por memorização de casos, mas por um raciocínio generalizável.
Implicações e desafios
Os achados deste estudo trazem à tona uma questão fascinante: devemos comparar os sistemas de IA de ponta a médicos individuais ou a equipes hospitalares completas, com generalistas e especialistas?
Hoje, a medicina é tão vasta que nenhum ser humano consegue dominar tudo. Por isso, temos generalistas e especialistas que trabalham juntos. O que a IA de ponta está mostrando é uma versatilidade notável, combinando o alcance do generalista com a profundidade do especialista. Isso levanta a possibilidade de uma "superinteligência médica" artificial que não apenas complemente, mas talvez até supere, o desempenho de um único médico humano em problemas complexos.
Essa abordagem de orquestração com múltiplos "agentes" ou "personas" dentro de um único LM é uma ideia poderosa. Ela simula um processo de pensamento colaborativo, onde diferentes perspectivas e especialidades são combinadas para chegar a um diagnóstico mais preciso e eficiente. É algo que a gente já faz no desenvolvimento de software, com equipes multifuncionais, mas aplicado ao raciocínio diagnóstico.
Uma crítica
É inegável que o MAI-DxO e o SDBench representam um avanço significativo. No entanto, como em qualquer tecnologia nova, há pontos a serem considerados e comparados.
- Generalização para o mundo real vs. casos de alta dificuldade: O estudo utiliza casos do NEJM-CPC, que são propositalmente difíceis e curados pedagogicamente. Isso é ótimo para testar os limites dos modelos, mas não reflete a distribuição de doenças no mundo real, onde a maioria dos pacientes tem condições comuns ou benignas. Não sabemos se o desempenho estelar do MAI-DxO se generaliza para o dia a dia clínico, e nem se ele é propenso a falsos positivos em cenários de baixo risco. Sistemas de IA mais antigos, baseados em modelos probabilísticos Bayesianos (como o Pathfinder, da década de 80), também prometiam diagnóstico especialista, mas esbarravam na dificuldade de adquirir dados detalhados e curados por especialistas sobre as relações probabilísticas entre achados e doenças. Os LMs contornam isso ao aprenderem padrões de texto de vastos volumes de dados médicos, mas a "curadoria pedagógica" dos casos NEJM ainda é um fator.
- Custo e aplicabilidade: Embora o estudo calcule o "custo" em dólares, a aplicabilidade em diferentes sistemas de saúde (públicos vs. privados, EUA vs. Brasil, etc.) é complexa. Custos de testes variam demais, e há outros custos implícitos (tempo de médico, manutenção de equipamentos, deslocamento do paciente) que não são totalmente capturados no estudo. Além disso, o estudo simplifica a "visita médica" para um custo fixo de $300, o que pode não refletir a realidade em muitos lugares. Em um cenário como o SUS, por exemplo, o custo de um exame é drasticamente diferente do custo em um hospital privado nos EUA.
- A "caixa preta" dos LMs vs. sistemas baseados em regras: Embora o MAI-DxO adicione uma camada de orquestração "transparente" (com os "Doutores" virtuais), o raciocínio fundamental de cada "Doutor" ainda é baseado em um LM, que é uma caixa preta em sua essência. Sistemas de IA mais antigos, baseados em regras ou redes Bayesianas explícitas, eram mais interpretáveis. No diagnóstico médico, a interpretabilidade (saber por que o sistema chegou a um diagnóstico) é crítica para a confiança e para que os médicos possam validar as sugestões. O MAI-DxO tenta mitigar isso com os papéis do Dr. Desafiador e Dr. Checklist, mas ainda não é totalmente transparente como um sistema baseado em conhecimento explícito. Falei sobre isso aqui um tempo atrás.
- Limitações do estudo com humanos: Os médicos humanos no estudo foram impedidos de usar recursos externos (Google, ChatGPT, etc.), o que não reflete a prática real. Na vida de um médico, consultar fontes de informação ou colegas é parte do processo diagnóstico. Isso pode ter superestimado a diferença entre humanos e IA. O objetivo, claro, foi isolar a capacidade de raciocínio, mas é importante ter isso em mente.
- Multimodalidade: O estudo se concentra em dados textuais e de custo. Na prática clínica, imagens (raio-X, tomografias, ressonâncias), sons (batimentos cardíacos, pulmonares) e outros dados sensoriais são cruciais. A incorporação dessas modalidades é o próximo passo natural e pode impulsionar ainda mais a precisão e a eficiência.
- Viés nos dados de treinamento: Embora o estudo use casos recentes que podem estar fora do cutoff de treinamento dos modelos, os LMs são treinados em vastos corpus de texto da internet, que podem conter vieses históricos ou de gênero em relação a certas condições médicas. Isso é uma preocupação constante em IA e deve ser monitorado em futuras aplicações clínicas.
Apesar dessas considerações, a capacidade de modelar explicitamente diagnósticos diferenciais de trabalho e raciocinar sobre o valor informacional e o custo dos testes diagnósticos é um avanço notável. A arquitetura do MAI-DxO, sendo agnóstica ao modelo subjacente, é uma jogada inteligente, diminuindo a "dependência de fornecedor" e permitindo que sistemas de saúde se beneficiem das melhores inovações sem ter que "correr atrás" de cada nova versão de LM.
O futuro da IA na saúde
As implicações desse trabalho são vastas. Sistemas como o MAI-DxO podem ser um divisor de águas, especialmente em regiões com escassez de profissionais de saúde, permitindo que médicos generalistas tenham acesso a uma capacidade diagnóstica "superhumana". Pense em um médico de família em uma área remota no Brasil, sem acesso fácil a especialistas. Uma ferramenta dessas pode ser crucial.
Se essa ferramenta for offline, melhor ainda. Como disse aqui neste post.
A ideia de "diretamente ao consumidor" (smartphone-based triage) é intrigante, mas levanta sérias questões de segurança, regulamentação e privacidade de dados. Por enquanto, o foco deve ser no auxílio a profissionais.
No fim das contas, a IA não vai substituir o médico. Não é sobre isso. É sobre aumentar as capacidades dos profissionais de saúde, permitir que eles tomem decisões mais informadas e eficientes, e, em última instância, melhorar os resultados para os pacientes. A gente está construindo ferramentas que podem ser como um "colega de equipe" com conhecimento enciclopédico e capacidade de raciocínio incansável, ajudando a "pensar diferente" e a não ficar preso ao primeiro pensamento. É um futuro onde a tecnologia atua como um catalisador para um cuidado à saúde mais acessível e de maior qualidade. Isso realmente me deixa animado para o que vem por aí.
É crucial que, daqui para frente, desenvolvamos mais benchmarks que reflitam a prevalência de doenças no mundo real, não apenas os casos mais complexos. Isso nos dará uma imagem mais completa das limitações e oportunidades. E, claro, a metodologia de "achados sintéticos" do Gatekeeper pode ajudar a criar mais casos interativos em larga escala para treino e avaliação. Quem sabe, até para a educação médica, simulando ambientes de prática para estudantes e profissionais.
O caminho para a "superinteligência médica" é longo, mas estudos como este mostram que estamos na trilha certa, construindo sistemas que não apenas diagnosticam, mas também raciocinam de forma iterativa e consciente. É um passo enorme para uma medicina mais inteligente e eficiente.
Fonte:
Comments